2026.1.5
投稿者「cacsd」のアーカイブ
非線形シミュレーション(旧版)
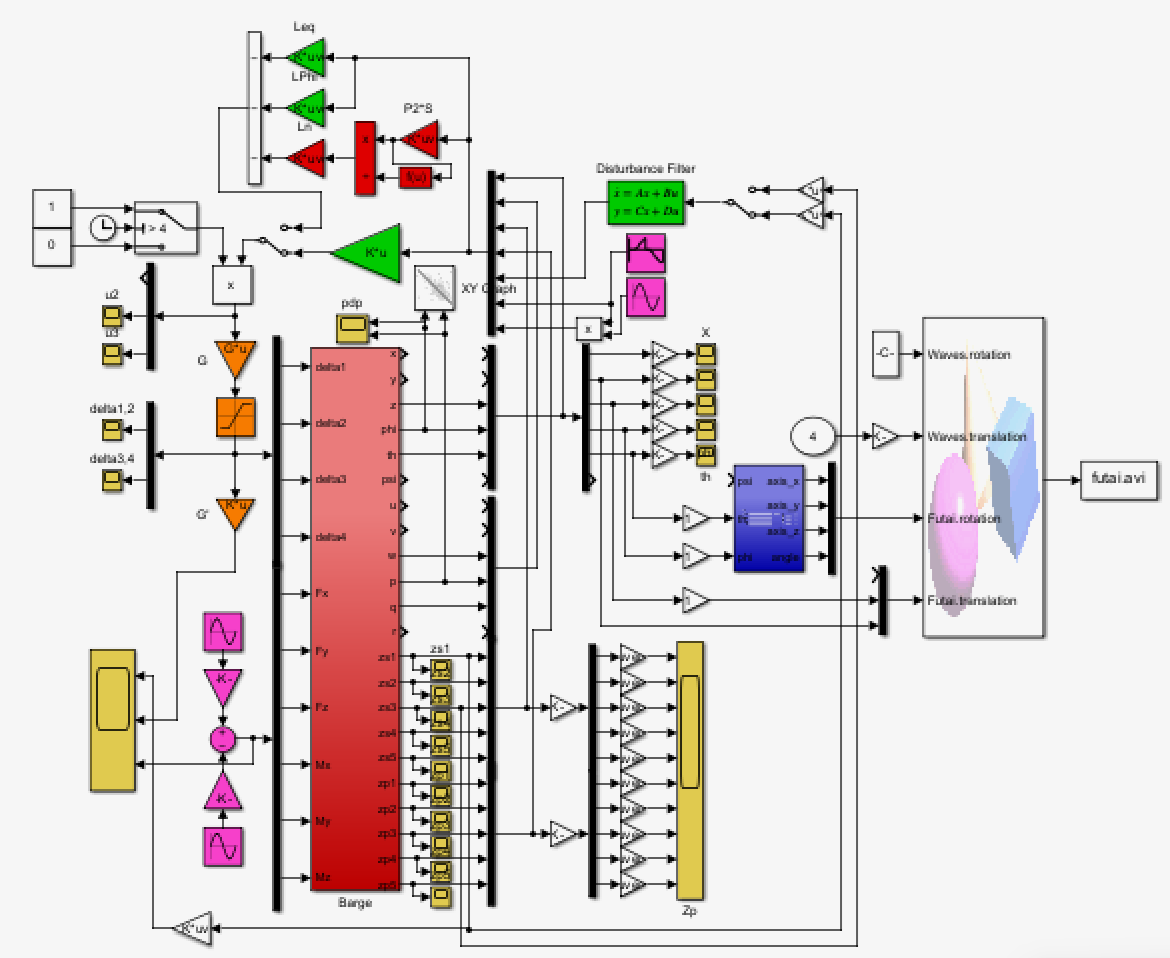
●制御対象(赤)
\left\{\begin{array}{l}
\dot{\vec x}=A(T_w){\vec x}+B(T_w)\vec{u}+B_w(T_w,\beta){\vec w}(T_w),\ {\vec x}(0)={\vec x}_0\\
{\vec y}_M=C_M{\vec x}\\
y=\underbrace{C_SC_M}_{C}{\vec x}
\end{array}\right.
●外乱信号(赤紫)
{\vec w}(T_w)=\left[\begin{array}{l}
H_w\sin\frac{2\pi}{T_w} t \\
H_w\cos\frac{2\pi}{T_w} t
\end{array}\right]
不規則波については時系列データを準備。
●外乱推定に用いる観測変数(緑)
y_d=C_d{\vec x}
主に制御点の縦変位を取る。
●外乱フィルタ(緑)
\dot{\hat{\vec x}}_d=A_d(T_w)\hat{{\vec x}}_d+B_d(T_w){y}_d,\ \hat{x}_d(0)=0
●非線形要素
-スラスタ伝達静特性:3次関数(V-F表)、入力電圧不感帯-1V~0V
-スラスタ伝達動特性:1次遅れ、時定数1/sqrt(50)、2/sqrt(50)、…
-スラスタ入力電圧リミッタ:±2.5V、±5V
●LQ制御/H∞制御
\vec{u}=-F(T_w)\vec{x}
●LQIM制御/H∞IM制御
\vec{u}=-F(T_w)\vec{x}-F_d(T_w)\hat{\vec{x}}_d
●SM制御



このとき、次の諸ケースについて、非線形シミュレーションを行ないます。ただし、短周期は 、長周期は
、長周期は とします。
とします。
| 制御方式 | 横波短周期 | 横波長周期 | 斜波短周期 | 斜波長周期 |
|---|---|---|---|---|
| LQ制御 | Case 4.1 | Case 4.2 | Case 4.3 | Case 4.4 |
| H∞制御 | Case 4.5 | Case 4.6 | Case 4.7 | Case 4.8 |
| SM制御 | Case 4.9 | Case 4.10 | Case 4.11 | Case 4.12 |
| LQIM制御 | Case 4.13 | Case 4.14 | Case 4.15 | Case 4.16 |
| H∞IM制御 | Case 4.17 | Case 4.18 | Case 4.19 | Case 4.20 |
| 制御方式 | 不規則波1 | 不規則波2 | 時間遅れ | 入力電圧制限 |
|---|---|---|---|---|
| LQ制御 | Case 5.1 | Case 5.2 | Case 5.3 | Case 5.4 |
| H∞制御 | Case 5.5 | Case 5.6 | Case 5.7 | Case 5.8 |
| SM制御 | Case 5.9 | Case 5.10 | Case 5.11 | Case 5.12 |
| LQIM制御 | Case 5.13 | Case 5.14 | Case 5.15 | Case 5.16 |
| H∞IM制御 | Case 5.17 | Case 5.18 | Case 5.19 | Case 5.20 |
LQ制御
Case 4.1(横波、短周期規則波) Case 4.2(横波、長周期規則波)
Case 4.3(斜波、短周期規則波) Case 4.4(斜波、長周期規則波)
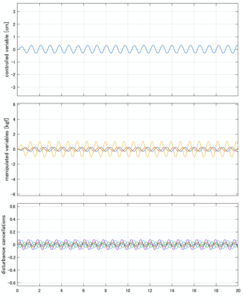
Case 5.1(横波、不規則波1)
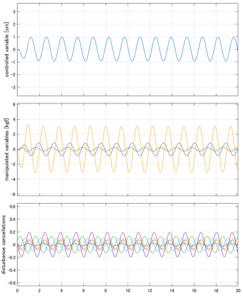
Case 5.2(横波、不規則波2)
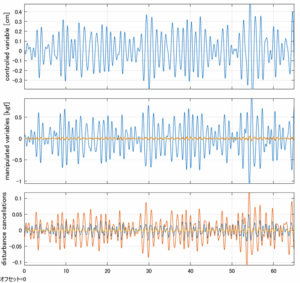
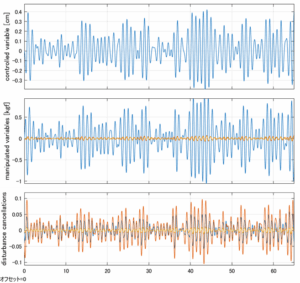
Case 5.3(横波、時間遅れ1秒) Case 5.4(横波、リミッタ2.5V)
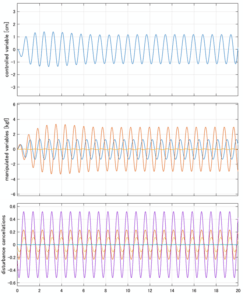
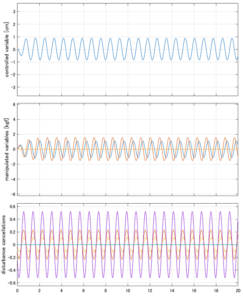
H∞制御
Case 4.5(横波、短周期規則波) Case 4.6(横波、長周期規則波)
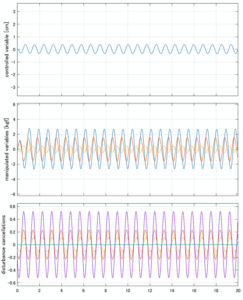
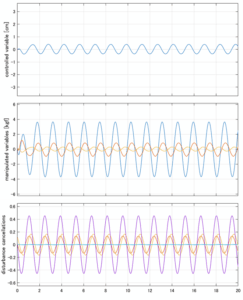
Case 4.7(斜波、短周期規則波) Case 4.8(斜波、長周期規則波)
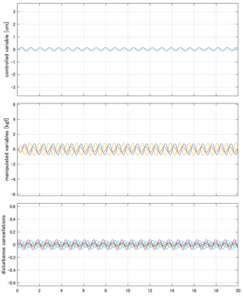
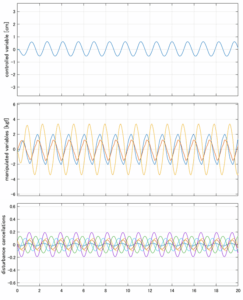
Case 5.5(横波、不規則波1)
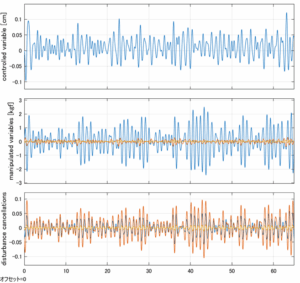
Case 5.6(横波、不規則波2)
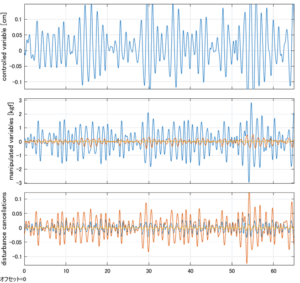
Case 5.7(横波、時間遅れ1秒) Case 5.8(横波、リミッタ2.5V)
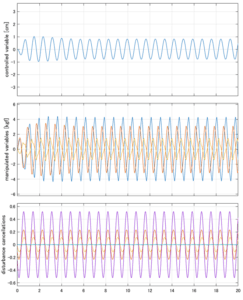
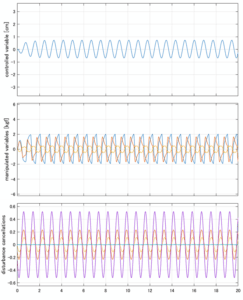
SM制御
Case 4.9(横波、短周期規則波)
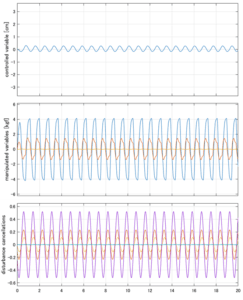
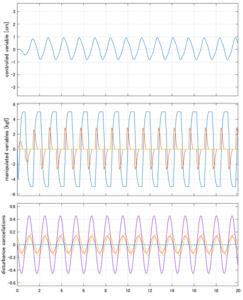
Case 4.11(斜波、短周期規則波) Case 4.12(斜波、長周期規則波)
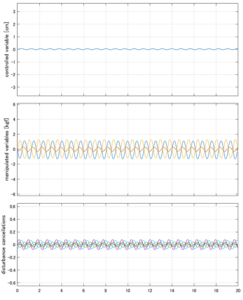
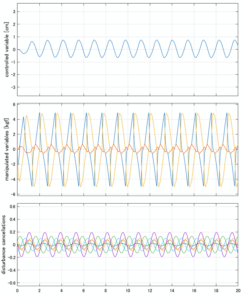
Case 5.9(横波、不規則波1)
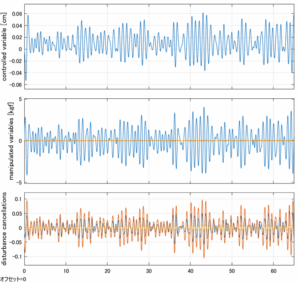
Case 5.10(横波、不規則波2)
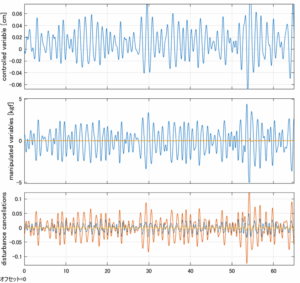
Case 5.11(横波、時間遅れ1秒) Case 5.12(横波、リミッタ2.5V)
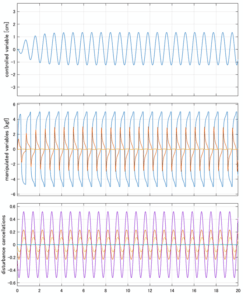
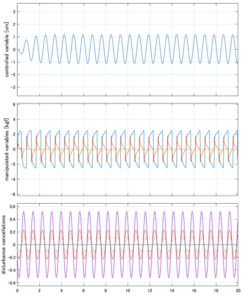
LQIM制御
Case 4.13(横波、短周期規則波) Case 4.14(横波、長周期規則波)
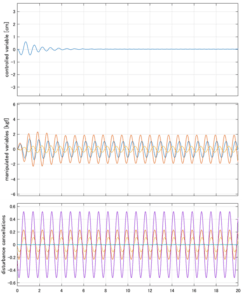
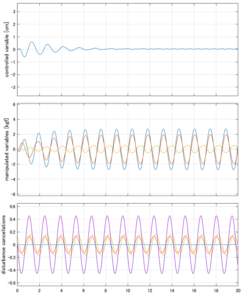
Case 4.15(斜波、短周期規則波) Case 4.16(斜波、長周期規則波)
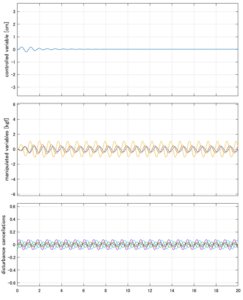
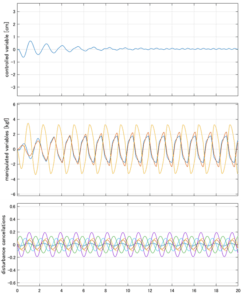
Case 5.13(横波、不規則波1)
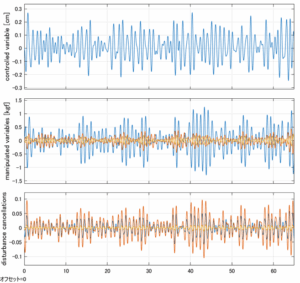
Case 5.14(横波、不規則波2)
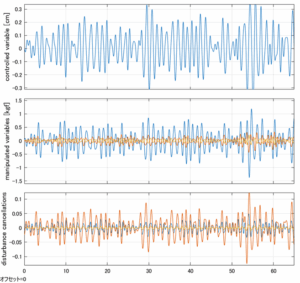
Case 5.15(横波、時間遅れ) Case 5.16()
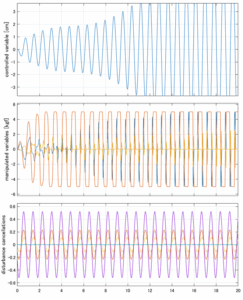
H∞IM制御
Case 4.17(横波、短周期規則波) Case 4.18(横波、長周期規則波)
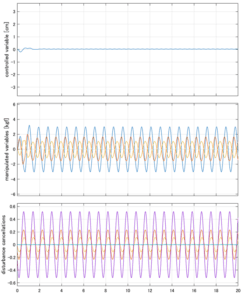
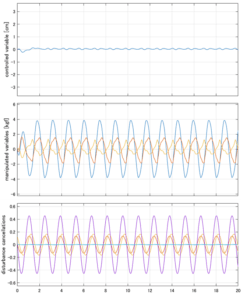
Case 4.19(斜波、短周期規則波) Case 4.20(斜波、長周期規則波)
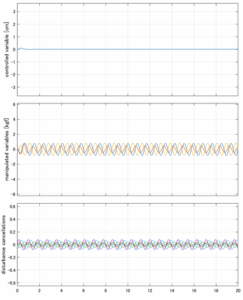
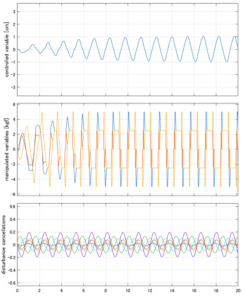
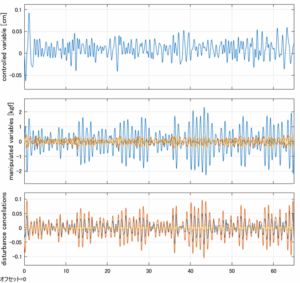
Case 5.17(横波、不規則波1)
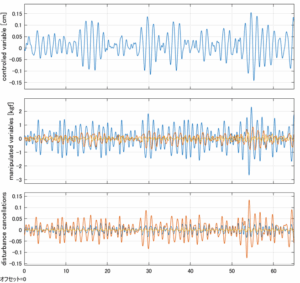
Case 5.18(横波、不規則波2)
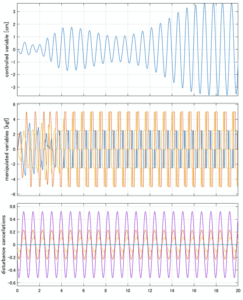
Case 5.19(横波、時間遅れ) Case 5.20()
SM制御(旧版)
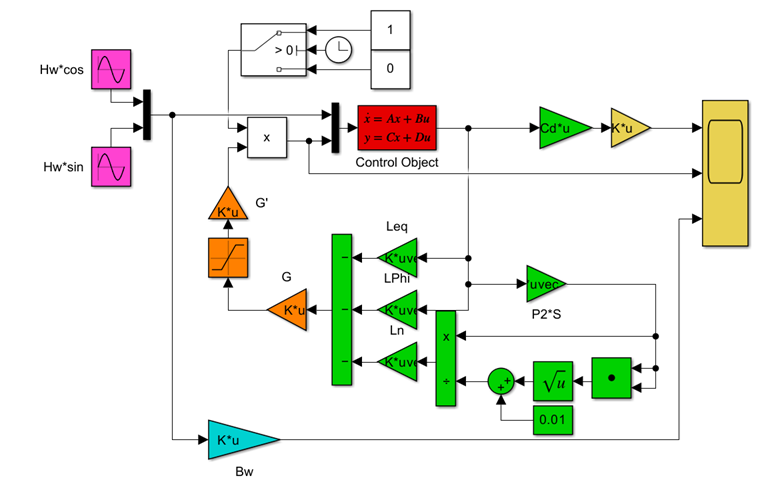
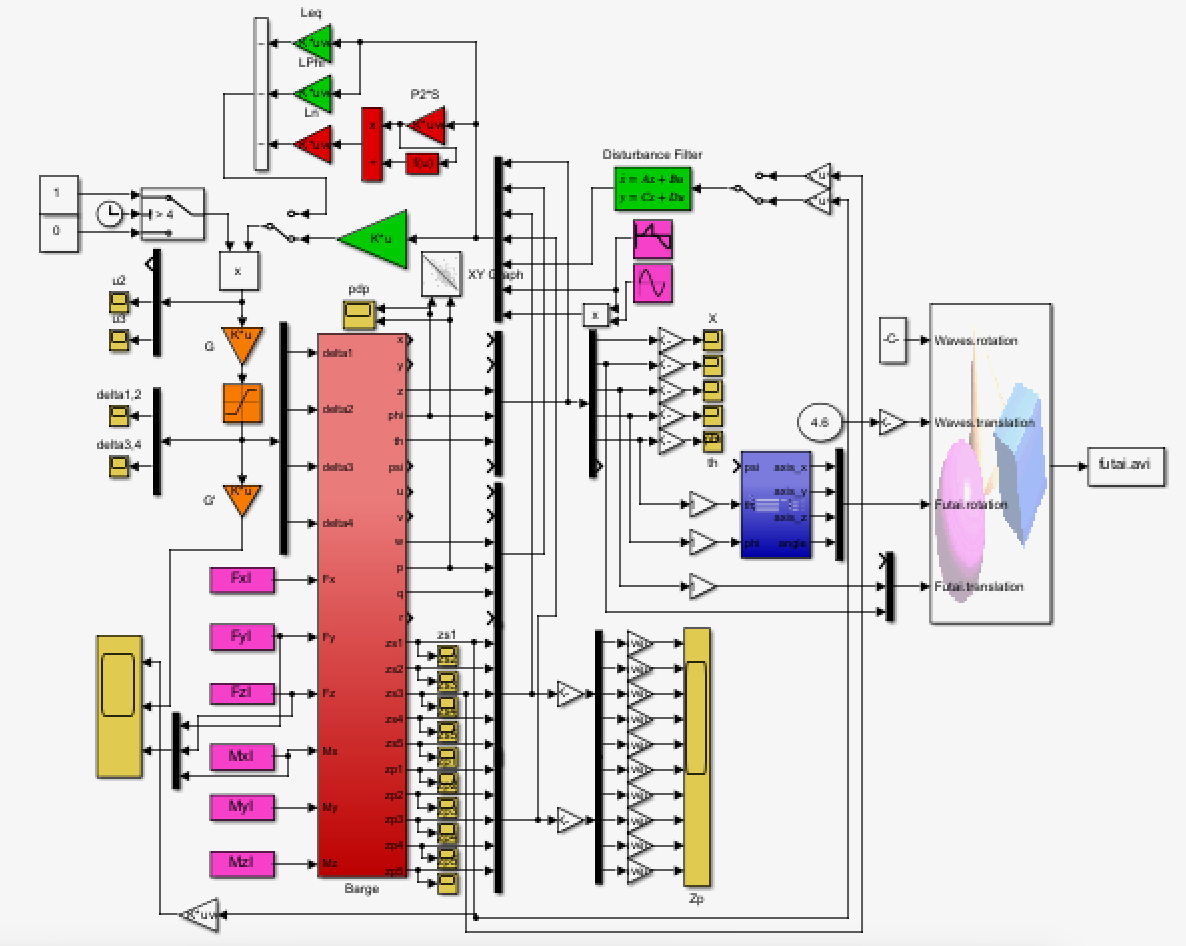
●制御対象(赤)
\left\{\begin{array}{l}
\dot{\vec x}=A(T_w){\vec x}+B(T_w)\vec{u}+B_w(T_w,\beta){\vec w},\ {\vec x}(0)={\vec x}_0\\
{\vec y}_M=C_M{\vec x}\\
y=\underbrace{C_SC_M}_{C}{\vec x}
\end{array}\right.
●外乱信号(赤紫)
{\vec w}=\left[\begin{array}{l}
H_w\sin\frac{2\pi}{T_w} t \\
H_w\cos\frac{2\pi}{T_w} t
\end{array}\right]
●SM制御則
このとき、次の12ケースについて、線形シミュレーションを行ないます。ただし、短周期は、長周期はとします。
| モデル/制御 | 横波短周期 | 横波長周期 | 斜波短周期 | 斜波長周期 |
|---|---|---|---|---|
| 2次系/SM | Case 3.1 | Case 3.2 | Case 3.3 | Case 3.4 |
| 4次系/SM | Case 3.5 | Case 3.6 | Case 3.7 | Case 3.8 |
| 6次系/SM | Case 3.9 | Case 3.10 | Case 3.11 | Case 3.12 |
|
|
以下に、シミュレーション結果を示します。各ケースについて左図がSM制御系の応答を示しています。左図上段は制御点の応答[cm]、左図中段は操作入力[kgf]、左図下段は波浪力[kgf]を示しています。4秒までは制御なしで、4秒以降が制御ありです。制御点は横波・斜波とも右舷船首S1を取っています(横波の場合、右舷制御点の区別はありません)。また操作入力には5Vのリミッタを掛けています。
2次モデルに対するSM制御
Case 3.1(横波、短周期規則波) Case 3.1(横波、長周期規則波)
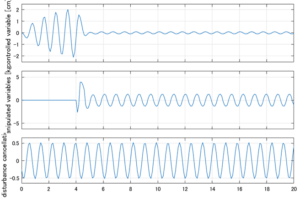
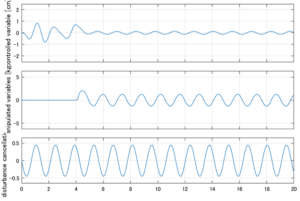
Case 3.3(斜波、短周期規則波) Case 3.4(斜波、長周期規則波)
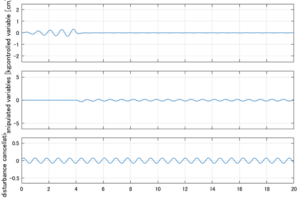
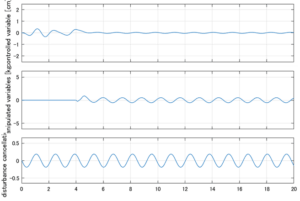
4次モデルに対するSM制御
Case 3.5(横波、短周期規則波) Case 3.6(横波、長周期規則波)
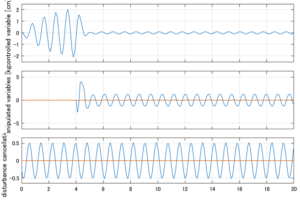
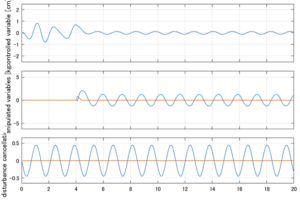
Case 3.7(斜波、短周期規則波) Case 3.8(斜波、長周期規則波)
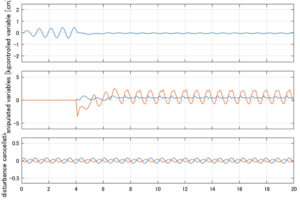
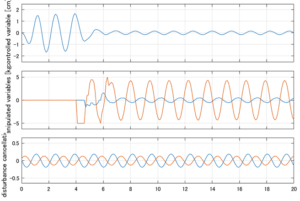
6次モデルに対するSM制御
Case 3.9(横波、短周期規則波) Case 3.10(横波、長周期規則波)
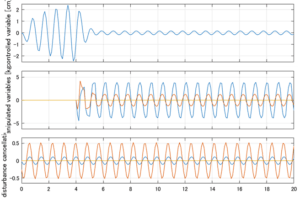
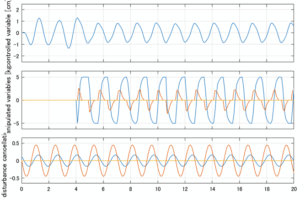
Case 3.11(斜波、短周期規則波) Case 3.12(斜波、長周期規則波)
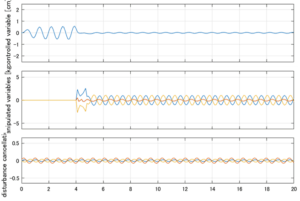
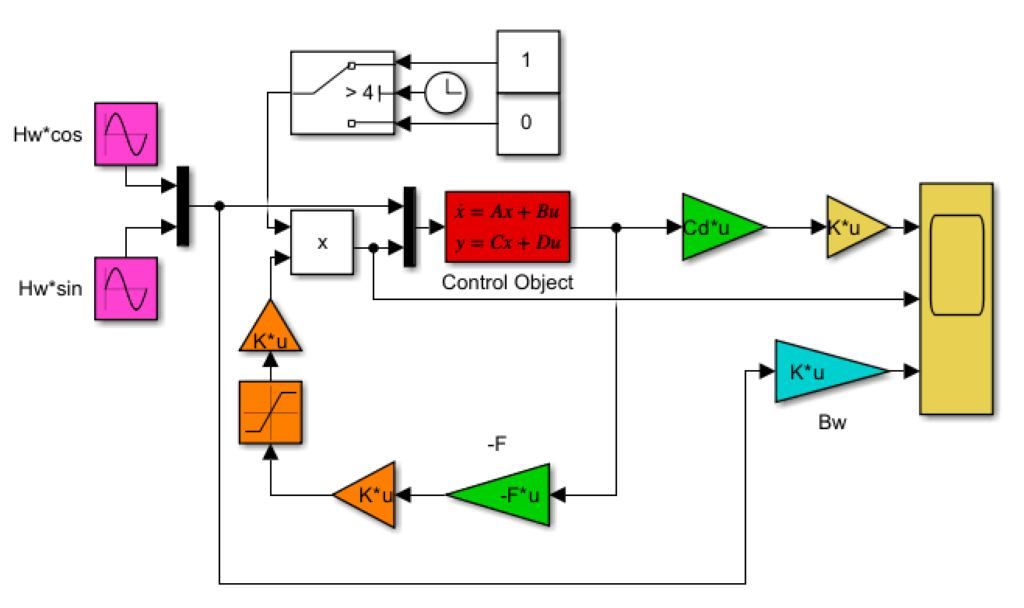
LQIM制御/H∞IM制御(旧版)
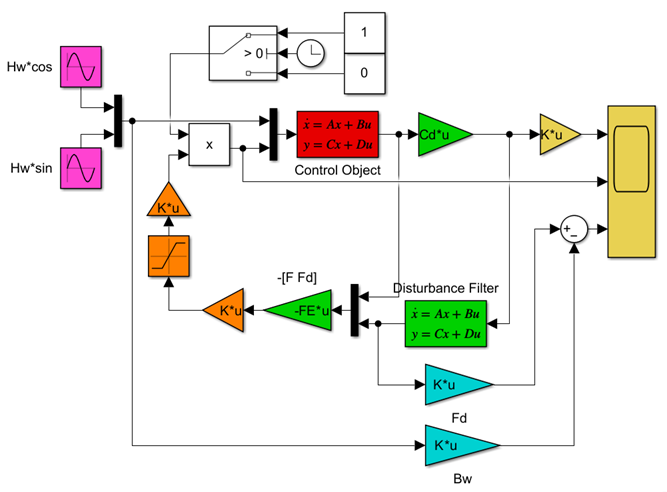
●制御対象(赤)
\left\{\begin{array}{l}
\dot{\vec x}=A(T_w){\vec x}+B(T_w)\vec{u}+B_w(T_w,\beta){\vec w},\ {\vec x}(0)={\vec x}_0\\
{\vec y}_M=C_M{\vec x}\\
y=\underbrace{C_SC_M}_{C}{\vec x}
\end{array}\right.
●外乱信号(赤紫)
{\vec w}=\left[\begin{array}{l}
H_w\sin\frac{2\pi}{T_w} t \\
H_w\cos\frac{2\pi}{T_w} t
\end{array}\right]
ここで、![H_w=0.01[m]](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-29ad5891f18c1e9f7fab6fb079df99b3_l3.png "Rendered by QuickLaTeX.com") とする。
とする。
●外乱推定に用いる観測変数(緑)
y_d=C_d{\vec x}
これは主に制御点の縦変位を取る。
●外乱フィルタ(緑)
\dot{\hat{\vec x}}_d=A_d(T_w)\hat{{\vec x}}_d+B_d(T_w){y}_d,\ \hat{x}_d(0)=0
●安定化制御則(緑)
\vec{u}=-F(T_w)\vec{x}-F_d(T_w)\hat{\vec{x}}_d
●推力配分(橙)
 は制御目的を達成するための望ましい
は制御目的を達成するための望ましい であるが、これは4つのスラスタに次式で配分する。
であるが、これは4つのスラスタに次式で配分する。
\underbrace{\left[\begin{array}{c}F_1\\F_2\\F_3\\F_4\end{array}\right]}_{\vec F}=
\underbrace{\frac{1}{4}\left[\begin{array}{rrr} 1 & 1 & -1 \\ 1 & 1 & 1 \\ 1 & -1 & 1\\1 & -1 & -1 \end{array}\right]}_{G^\dag}
\underbrace{\left[\begin{array}{c}F_z\\F_\phi\\F_\theta\end{array}\right]}_{\vec\tau}
●推力制限(橙)
その際、次の制約が課される。
F_{min}\le F_k\le F_{max}\quad(k=1,2,3,4)
上のシミュレータは、この制約を考慮したものとなっている。ここでは、F_{max}=5[kgf]、F_{min}=-5[kgf]を用いる(要チェック)。
●留意点
制約を受けた推力は次式で駆動力に変換されるが、推力制限がある場合は設計した駆動力が働かないので注意が必要である。
\underbrace{\left[\begin{array}{c}F_z\\F_\phi\\F_\theta\end{array}\right]}_{\vec\tau}=
\underbrace{\left[\begin{array}{rrrr} 1 & 1 & 1 & 1\\ 1 & 1 & -1 & -1\\ -1 & 1 & 1 & -1 \end{array}\right]}_{G}
\underbrace{\left[\begin{array}{c}F_1\\F_2\\F_3\\F_4\end{array}\right]}_{\vec F}
このとき、次の16ケースについて、上のシミュレータを用いてシミュレーションを行なう。ただし、短周期は、長周期はとする。
| モデル/制御 | 横波短周期 | 横波長周期 | 斜波短周期 | 斜波長周期 |
|---|---|---|---|---|
| 2次系/LQIM | Case 2.1 | Case 2.2 | Case 2.3 | Case 2.4 |
| 4次系/LQIM | Case 2.5 | Case 2.6 | Case 2.7 | Case 2.8 |
| 6次系/LQIM | Case 2.9 | Case 2.10 | Case 2.11 | Case 2.12 |
| 6次系/H∞IM | Case 2.13 | Case 2.14 | Case 2.15 | Case 2.16 |
|
|
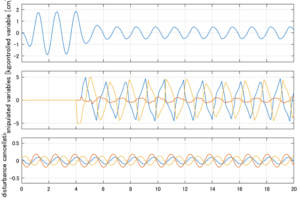
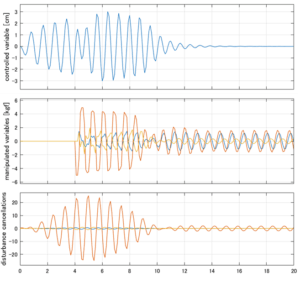
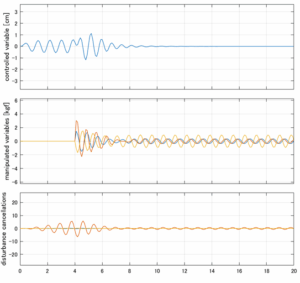
以下に、各ケースについてLQ制御系/H∞制御系の応答とゲイン線図を示す。前者の上段は制御点の応答[cm]、中段は操作入力[kgf]、下段は波浪外力[kgf]を示している。閉ループ系では
\dot{\vec x}=(A(T_w)-B(T_w)F(T_w)){\vec x}\underbrace{-B(T_w)F_d(T_w)\hat{\vec{x}}_d+B_w(T_w,\beta){\vec w}}_{相殺?}
が成り立つと思われる。左辺第2項(外乱推定項)と第3項(外乱項)が相殺するかどうかを下段で確認している。4秒までは制御なしで、4秒以降が制御ありの応答。制御点は横波・斜波とも右舷船首S1を取っている(横波の場合、右舷制御点の区別はない)。
●留意点
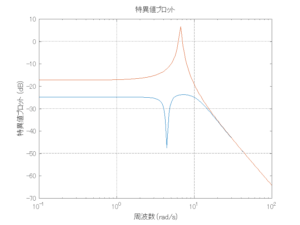
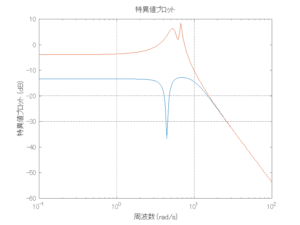
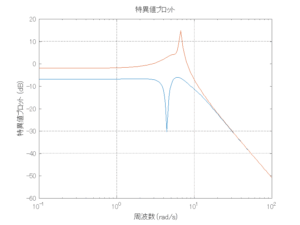
外乱から着目する制御点までのゲイン線図は、LQIM制御系の場合、波周波数においてピンポイントで低減され、H∞IM制御系の場合、波周波数近傍で低減されている。
2次モデルに対するLQIM制御
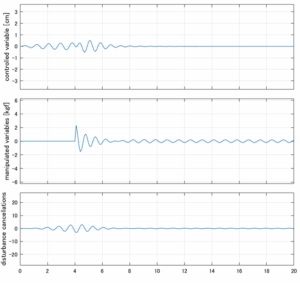
Case 2.1(横波、短周期規則波) Case 2.2(横波、長周期規則波)
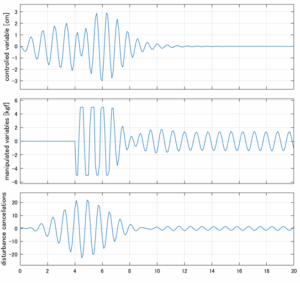
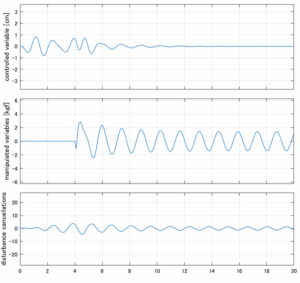
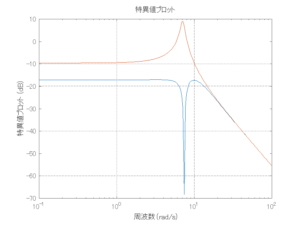
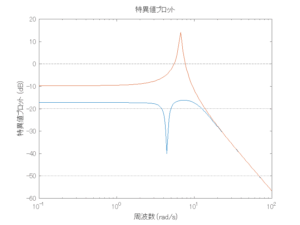
Case 2.3(斜波、短周期規則波) Case 2.4(斜波、長周期規則波)
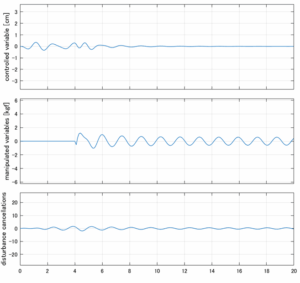
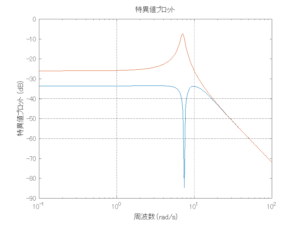
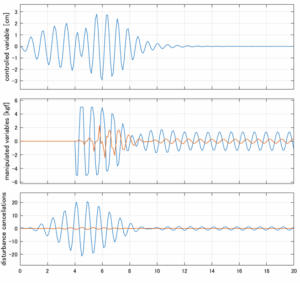
4次モデルに対するLQIM制御
Case 2.5(横波、短周期規則波) Case 2.6(横波、長周期規則波)
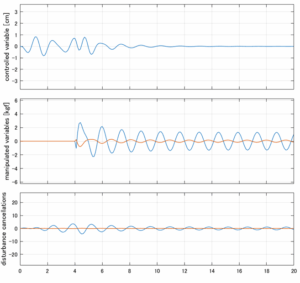
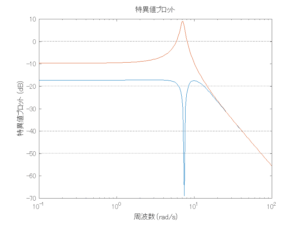
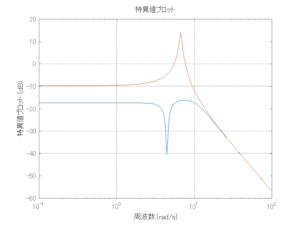
Case 2.7(斜波、短周期規則波) Case 2.8(斜波、長周期規則波)
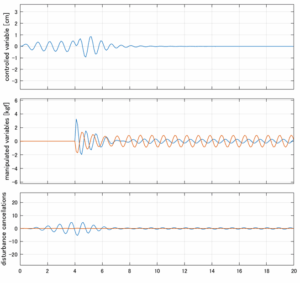
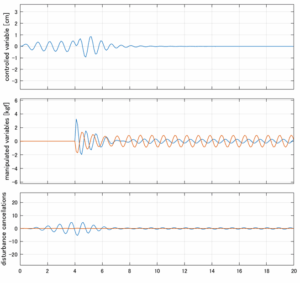
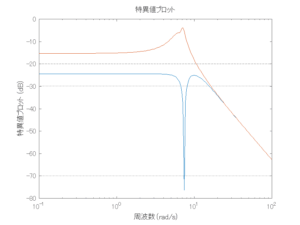
6次モデルに対するLQIM制御
Case 2.9(横波、短周期規則波) Case 2.10(横波、長周期規則波)
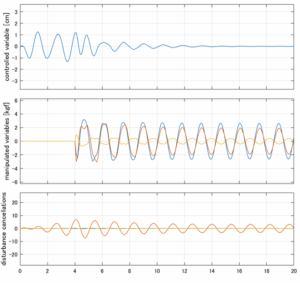
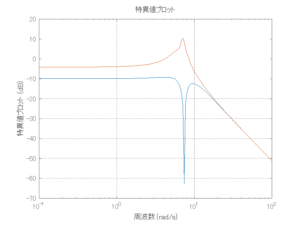
Case 2.11(斜波、短周期規則波) Case 2.12(斜波、長周期規則波)
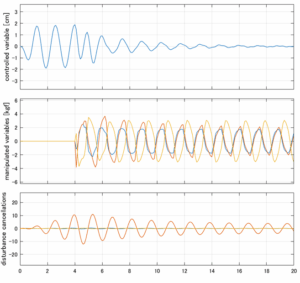
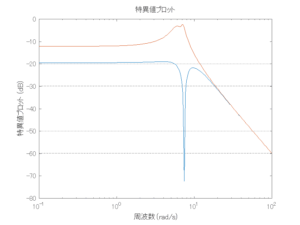
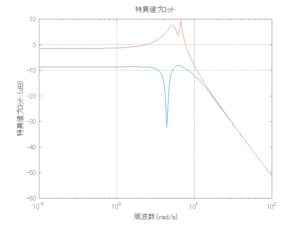
6次モデルに対するH∞IM制御
Case 2.13(横波、短周期規則波) Case 2.14(横波、長周期規則波)
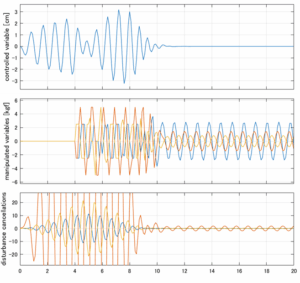
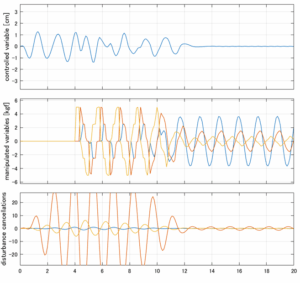
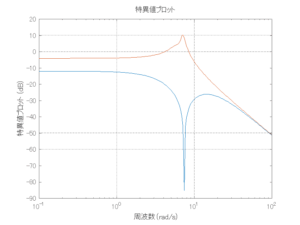
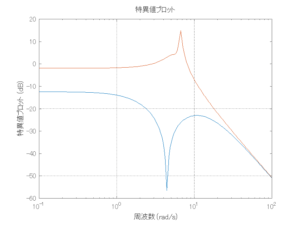
Case 2.15(斜波、短周期規則波) Case 2.16(斜波、長周期規則波)
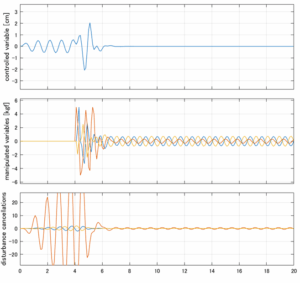
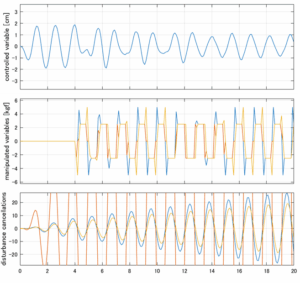
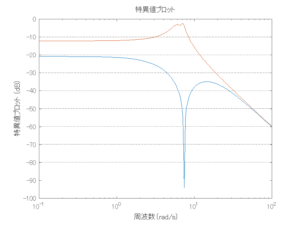
Case 2.16コメント
この場合だけ制御性能が劣化しているが、操作入力のリミッタを5Vから少し緩めたり、制御動作を4秒からでなく少し早めたりすれば、Case 2.13/14/15と同等になる。
LQ制御/H∞制御(旧版)
●制御対象(赤)
\left\{\begin{array}{l}
\dot{\vec x}=A(T_w){\vec x}+B(T_w)\vec{u}+B_w(T_w,\beta){\vec w},\ {\vec x}(0)={\vec x}_0\\
{\vec y}_M=C_M{\vec x}\\
y=\underbrace{C_SC_M}_{C}{\vec x}
\end{array}\right.
●外乱信号(赤紫)
{\vec w}=\left[\begin{array}{l}
H_w\sin\frac{2\pi}{T_w} t \\
H_w\cos\frac{2\pi}{T_w} t
\end{array}\right]
ここで、とする。
●安定化制御則(緑)
\vec{u}=-F(T_w)\vec{x}
●推力配分(橙)
は制御目的を達成するための望ましいであるが、これは4つのスラスタに次式で配分する。
\underbrace{\left[\begin{array}{c}F_1\\F_2\\F_3\\F_4\end{array}\right]}_{\vec F}=
\underbrace{\frac{1}{4}\left[\begin{array}{rrr} 1 & 1 & -1 \\ 1 & 1 & 1 \\ 1 & -1 & 1\\1 & -1 & -1 \end{array}\right]}_{G^\dag}
\underbrace{\left[\begin{array}{c}F_z\\F_\phi\\F_\theta\end{array}\right]}_{\vec\tau}
●推力制限(橙)
その際、次の制約が課される。
F_{min}\le F_k\le F_{max}\quad(k=1,2,3,4)
上のシミュレータは、この制約を考慮したものとなっている。
ここでは、F_{max}=2.5[kgf]、F_{min}=-2.5[kgf]を用いる(要チェック)。
●留意点
制約を受けた推力は次式で駆動力に変換されるが、推力制限がある場合は設計した駆動力が働かないので注意が必要である。
\underbrace{\left[\begin{array}{c}F_z\\F_\phi\\F_\theta\end{array}\right]}_{\vec\tau}=
\underbrace{\left[\begin{array}{rrrr} 1 & 1 & 1 & 1\\ 1 & 1 & -1 & -1\\ -1 & 1 & 1 & -1 \end{array}\right]}_{G}
\underbrace{\left[\begin{array}{c}F_1\\F_2\\F_3\\F_4\end{array}\right]}_{\vec F}
このとき、次の16ケースについて、上のシミュレータを用いてシミュレーションを行なう。ただし、短周期は、長周期はとする。
| モデル/制御 | 横波短周期 | 横波長周期 | 斜波短周期 | 斜波長周期 |
|---|---|---|---|---|
| 2次系/LQ | Case 1.1 | Case 1.2 | Case 1.3 | Case 1.4 |
| 4次系/LQ | Case 1.5 | Case 1.6 | Case 1.7 | Case 1.8 |
| 6次系/LQ | Case 1.9 | Case 1.10 | Case 1.11 | Case 1.12 |
| 6次系/H∞ | Case 1.13 | Case 1.14 | Case 1.15 | Case 1.16 |
|
|
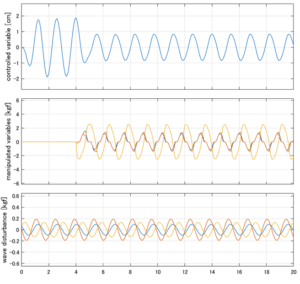
以下に、各ケースについてLQ制御系/H∞制御系の応答とゲイン線図を示す。前者の上段は制御点の応答[cm]、中段は操作入力[kgf]、下段は波浪外力[kgf]を示している。4秒までは制御なしで、4秒以降が制御ありの応答。制御点は横波・斜波とも右舷船首S1を取っている(横波の場合、右舷制御点の区別はない)。
2次モデルに対するLQ制御
2次モデルの状態変数はロールとその微分。ここではロールに浮体の半幅長さを掛けた制御点の縦変位の低減を図っている。
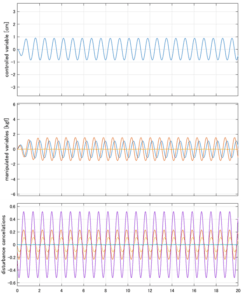
Case 1.1(横波、短周期規則波) Case 1.2(横波、長周期規則波)
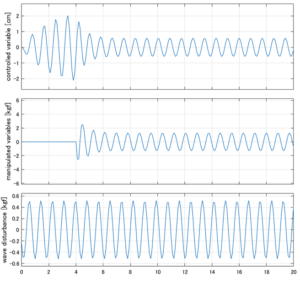
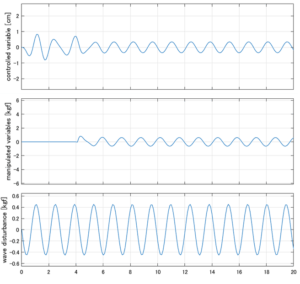
Case 1.1コメント
●応答図上段:横波を受けて4秒までは制御点の縦変位は2cm程度まで大きく出る。4秒になると制御が始まり、1/10の0.2㎝程度まで低減される。
●応答図下段:浮体が受ける波浪外力を表している。計算式は
 を用いている。4秒までは5つの山がありますが、これを受けて制御点にも5つの山があることに注意。そして、4秒付近で、波浪外力は次の山に向かって負から正の方向に働いている。
を用いている。4秒までは5つの山がありますが、これを受けて制御点にも5つの山があることに注意。そして、4秒付近で、波浪外力は次の山に向かって負から正の方向に働いている。
●応答図中段:この外力を打ち消すように、4秒から制御動作が始まる。
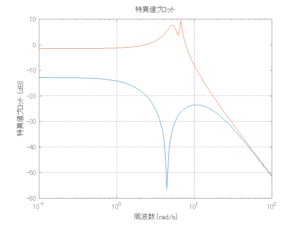
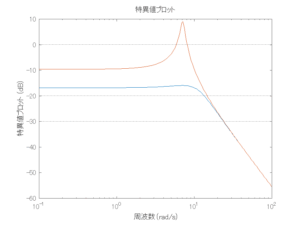
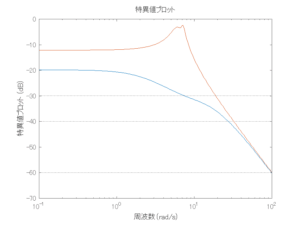
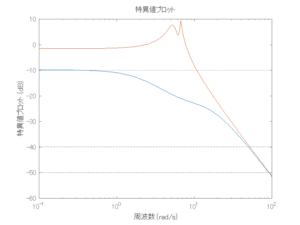
●波浪外力から制御点までのゲイン線図を、制御前の開ループ系(橙)と制御前の閉ループ系(青)について示している。波周期に対応する角周波数は [rad/sec]です。閉ループ系のゲイン線図から、開ループ系のピークが抑制されていることが分かる。-20dBは1/10を意味する。
[rad/sec]です。閉ループ系のゲイン線図から、開ループ系のピークが抑制されていることが分かる。-20dBは1/10を意味する。
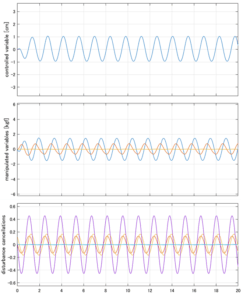
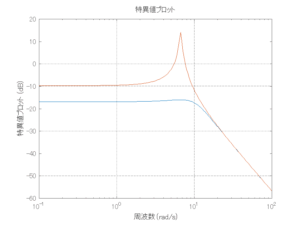
Case 1.2コメント
●波周期に対応する角周波数は [rad/sec]。閉ループ系のゲイン線図から、開ループ系のピークが抑制されていることが分かる。
[rad/sec]。閉ループ系のゲイン線図から、開ループ系のピークが抑制されていることが分かる。
Case 1.3(斜波、短周期規則波) Case 1.4(斜波、長周期規則波)
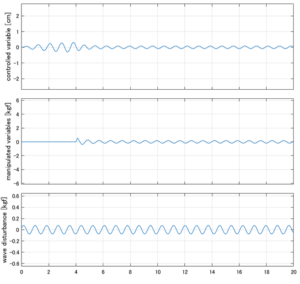
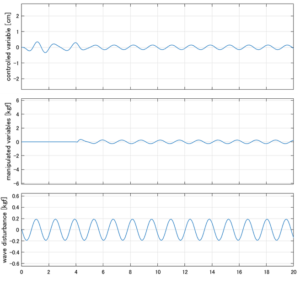
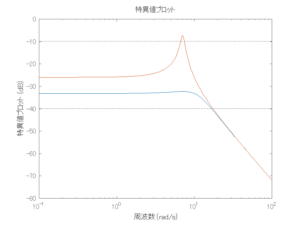
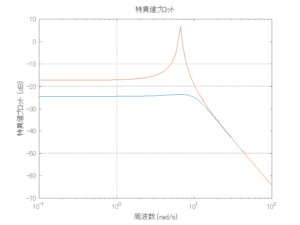
Case 1.3コメント
●斜波のときは必ずピッチが生じるが、ここではロールだけに注目している。浮体が受ける波浪外力はCase1.1に比べて小さくなっている。
Case 1.4コメント
●斜波のときは必ずピッチが生じるが、ここではロールだけに注目している。浮体が受ける波浪外力はCase1.2に比べて小さくなっている。
4次モデルに対するLQ制御
4次モデルの状態変数はロールとピッチ、およびそれらの微分。ここではロールとピッチから計算される制御点の縦変位(ヒーブは入らないことに注意)の低減を図っている。
Case 1.5(横波、短周期規則波) Case 1.6(横波、長周期規則波)
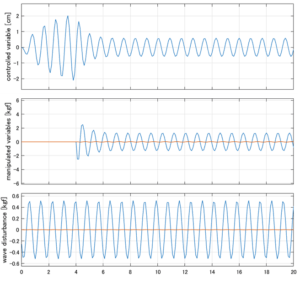
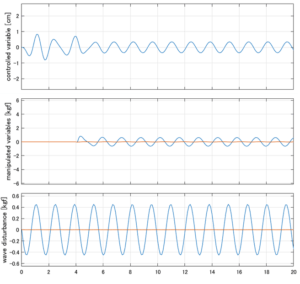
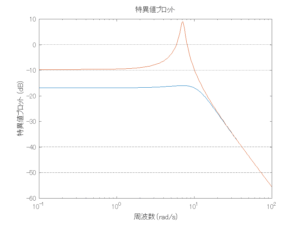
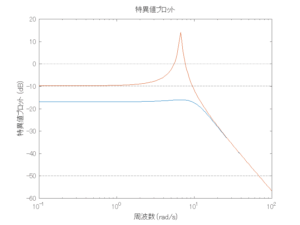
Case 1.5コメント
●横波の場合はピッチは誘起されないので、Case1.1と同じになる。
●応答図中段:ピッチが誘起されないので、ピッチ駆動力(橙)は零。
Case 1.6コメント
●横波の場合はピッチは誘起されないので、Case1.2と同じになる。
●応答図中段:ピッチが誘起されないので、ピッチ駆動力(橙)は零。
Case 1.7(斜波、短周期規則波) Case 1.8(斜波、長周期規則波)
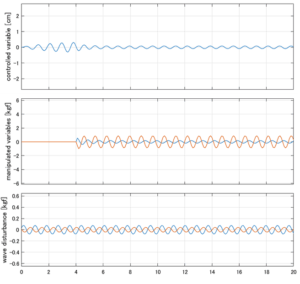
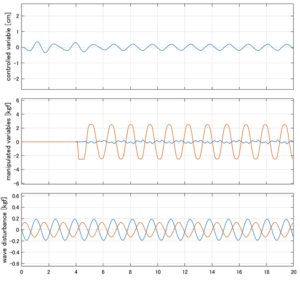
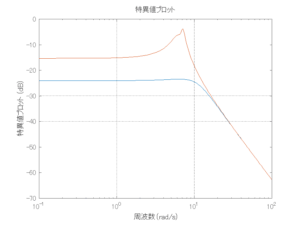
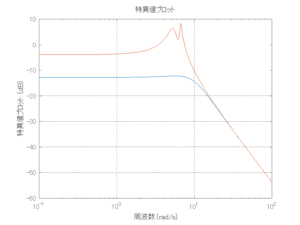
Case 1.7コメント
●応答図下段:ピッチ運動を誘起する波浪外力(橙)が生じている。計算式は  を用いています。
を用いています。
●応答図中段:ピッチ運動を抑制するピッチ駆動力(橙)が生じている。
Case 1.8コメント
●長周期斜波の場合の波浪外力は、短周期の場合に比べて、大き目に出る模様。
6次モデルに対するLQ制御
6次モデルの状態変数はヒーブとロール、ピッチ、およびそれらの微分。ここではヒーブとロール、ピッチから計算される制御点の縦変位(ヒーブが加わことに注意)の低減を図っている。
Case 1.9(横波、短周期規則波) Case 1.10(横波、長周期規則波)
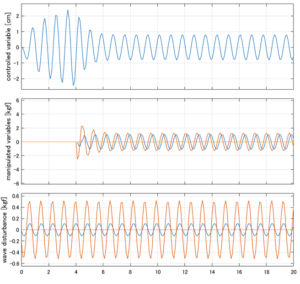
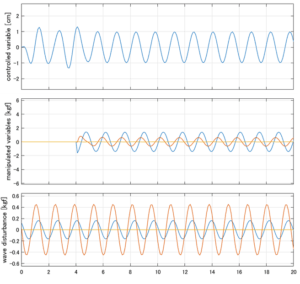
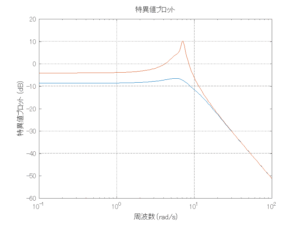
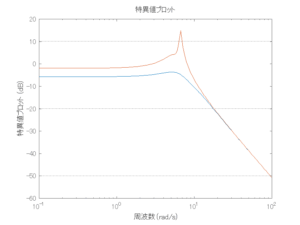
Case 1.9コメント
●横波の場合はピッチは誘起されないが、ヒーブが現れる。Case1.5との違いは、それに起因すると考えられる。
●応答図中段:青、赤、橙の順にヒーブ、ロール、ピッチに働く駆動力を表している。
●応答図下段:青、赤、橙の順にヒーブ、ロール、ピッチに働く波浪外力を表している。計算式は、それぞれ次を用いる。

Case 1.10コメント
●横波の場合はピッチは誘起されないが、ヒーブが現れます。Case1.6との違いは、それに起因すると考えられる。
Case 1.11(斜波、短周期規則波) Case 1.12(斜波、長周期規則波)
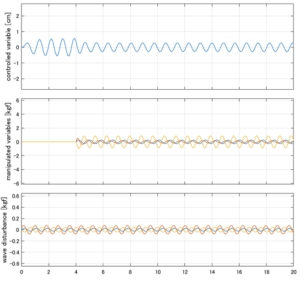
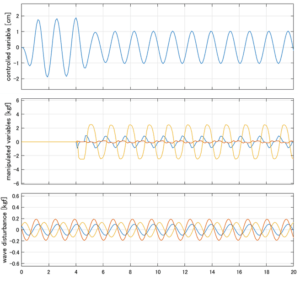
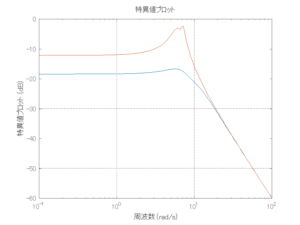
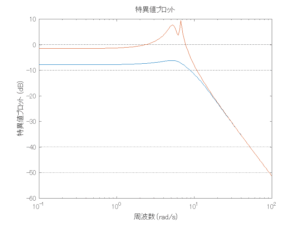
Case 1.11コメント
●斜波の場合はピッチが誘起され、ヒーブが現れる。Case1.7との違いは、それに起因すると考えらる。
Case 1.12コメント
●斜波の場合はピッチが誘起され、ヒーブが現れる。Case1.8との違いは、それに起因すると考えらる。
6次モデルに対するH∞制御
波浪外力から制御点までのゲイン線図は、LQ制御と比べて、波周期に対応する角周波数でより低減されていて、制御点縦変位の抑制も効いています。
Case 1.13(横波、短周期規則波) Case 1.14(横波、長周期規則波)
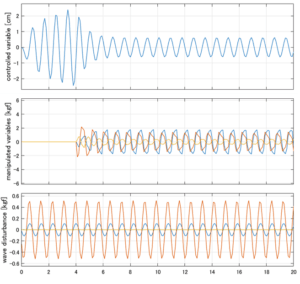
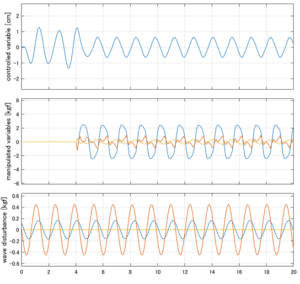
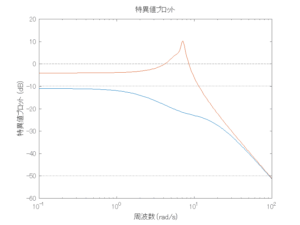
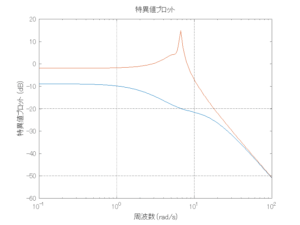
Case 1.13コメント
Case 1.14コメント
Case 1.15(斜波、短周期規則波) Case 1.16(斜波、長周期規則波)
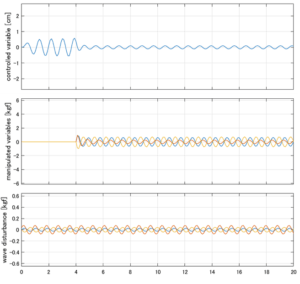
Case 1.15コメント
Case 1.16コメント
補遺A
| OptSeq |
|
設備を増設した場合
| OptSeq |
|
次船を含めた場合
| OptSeq |
|
リスケの手法
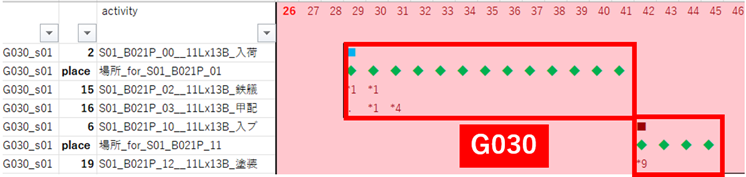
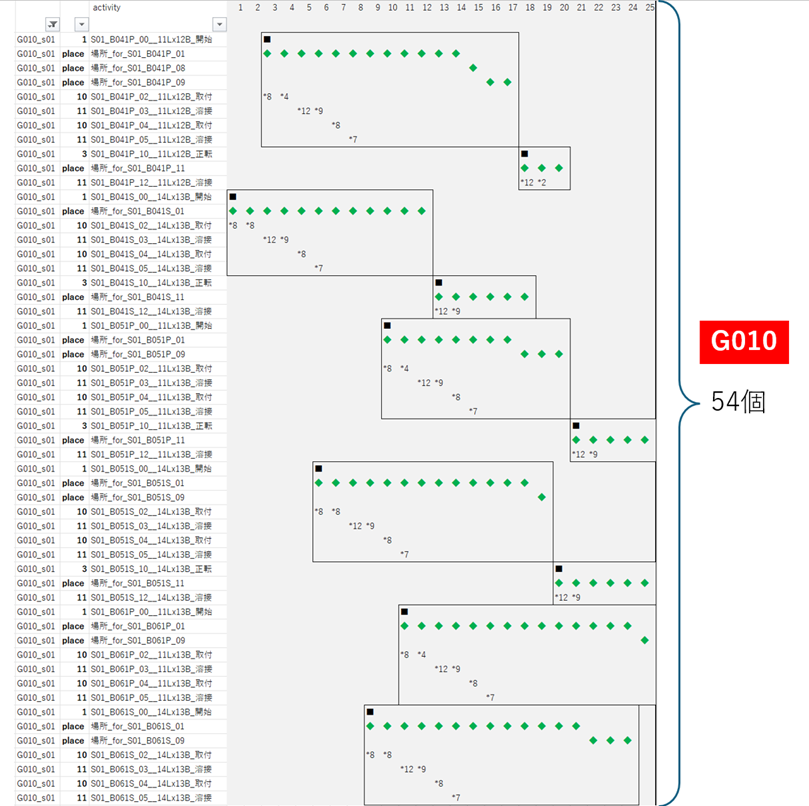
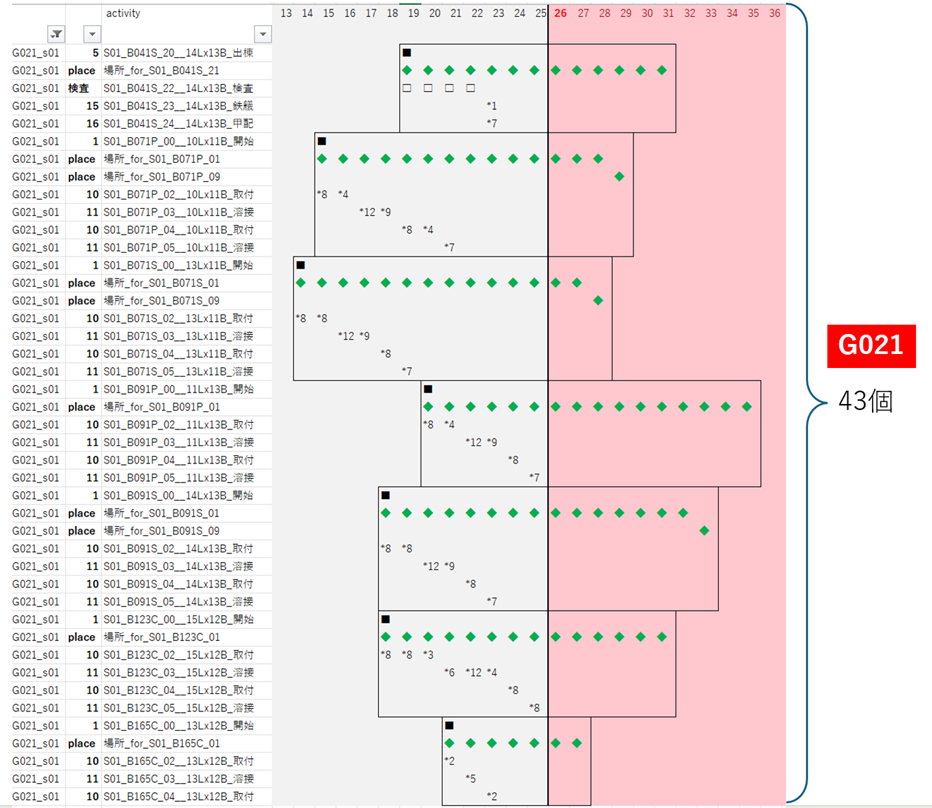
リスケアクティビティの分類
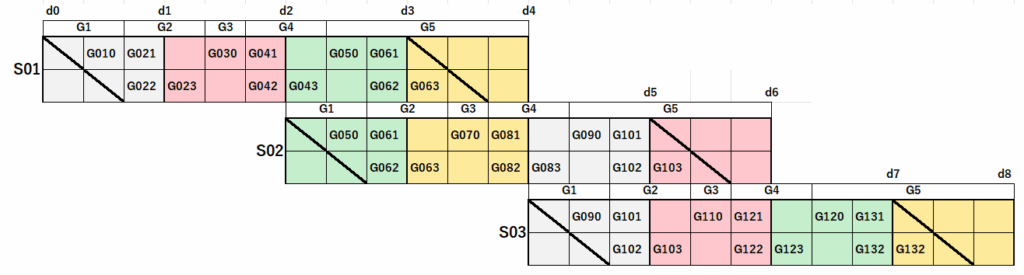
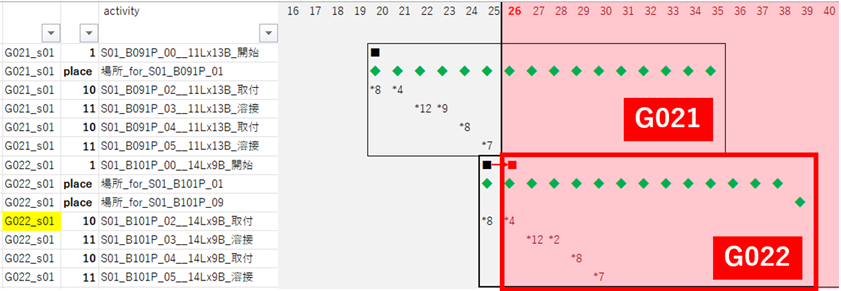

G010
G021
G022
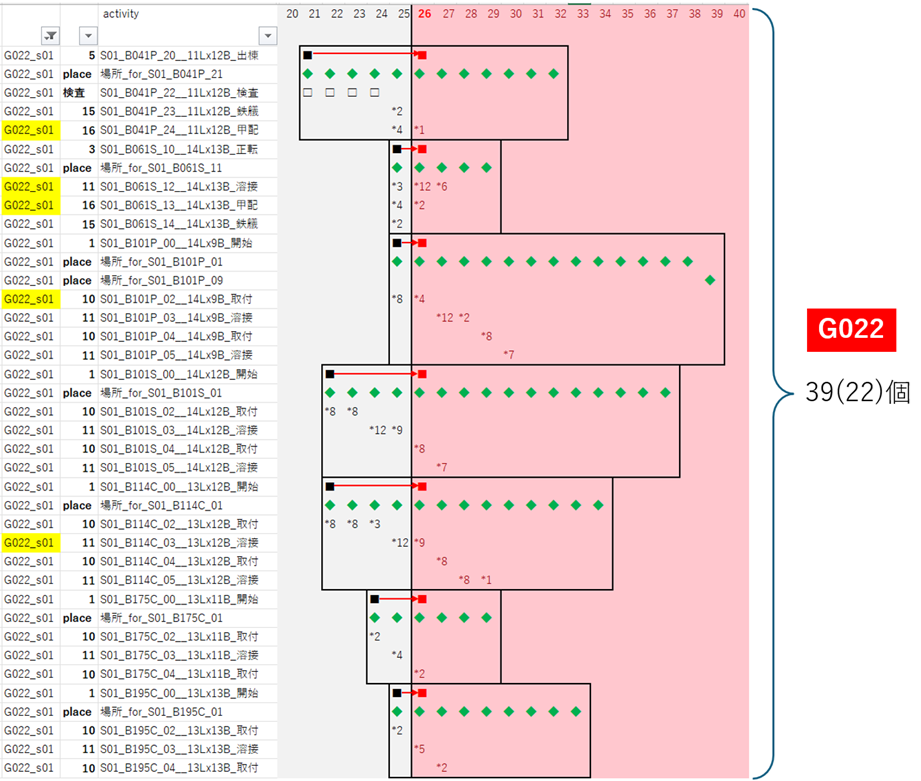
|
|
|
|
G030
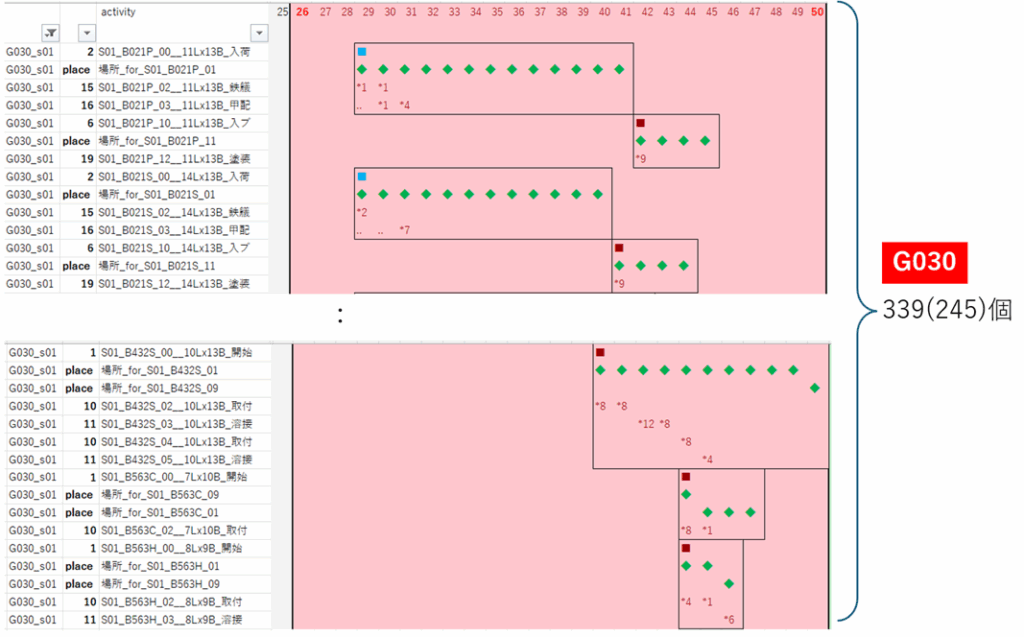
|
|
G041
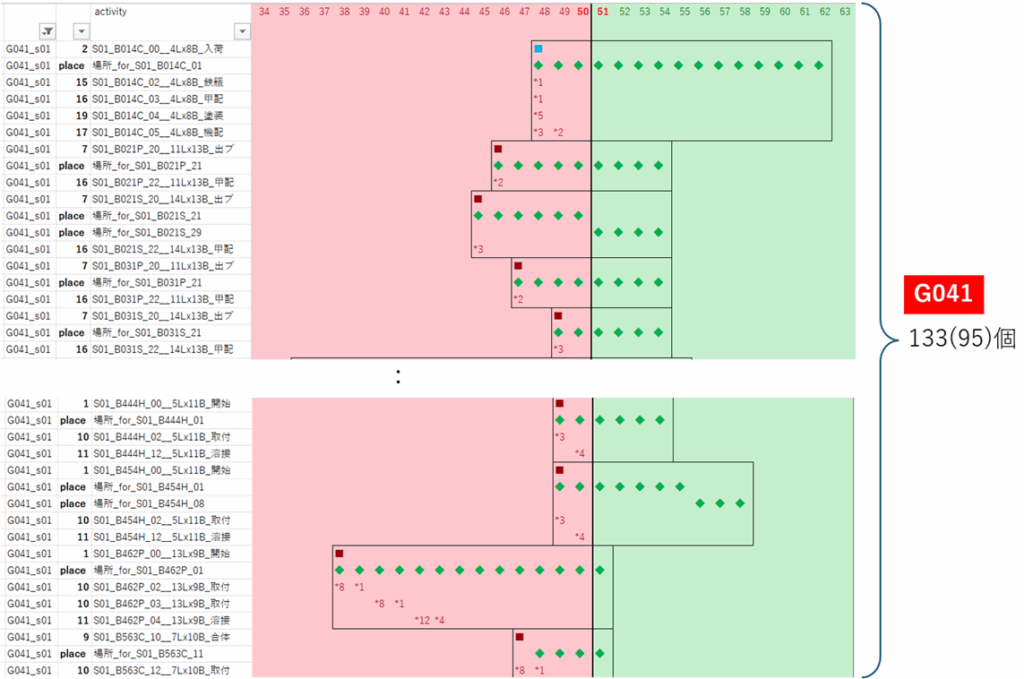
|
|
|
|
G042
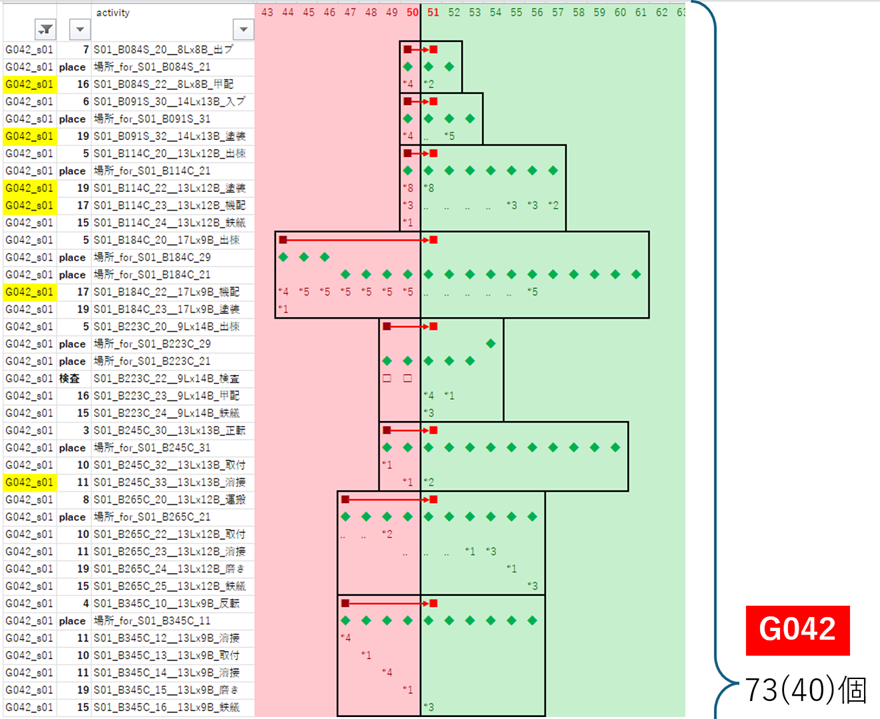
|
|
|
|
|
|
rcpsp71.py
|
|
|
|
|
|
|
|
補遺6
| OptSeq |
|