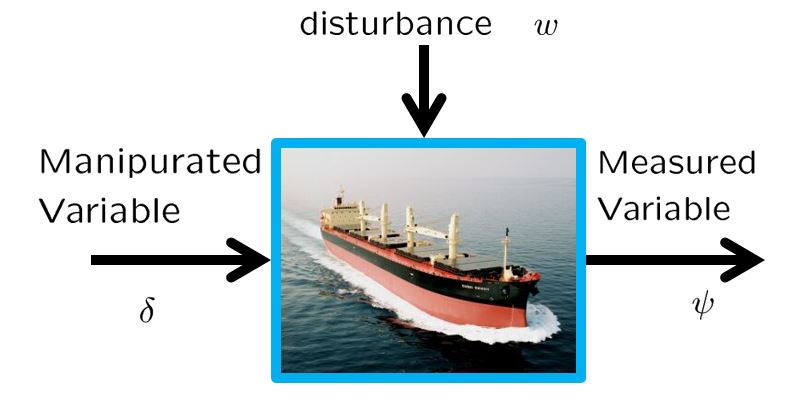
●For the directional control of a ship, consider the following NOMOTO model.

where  and
and

We assume the time lag  to take account of the delay to get the rudder effect. We use the same notation for the ship length assuming no confusion. The time constant
to take account of the delay to get the rudder effect. We use the same notation for the ship length assuming no confusion. The time constant  and gain constant
and gain constant  are varied according to the variation of forward speed
are varied according to the variation of forward speed  . From the following equation, it is clear that the rudder effect is proportional to the square of the forward speed.
. From the following equation, it is clear that the rudder effect is proportional to the square of the forward speed.

Given a nominal forward speed  , the following equation holds.
, the following equation holds.

where

●Zig-Zag Test: Neglecting the time lag and the forward speed variation, a simulation example of the Zig-Zag test is given as follows.
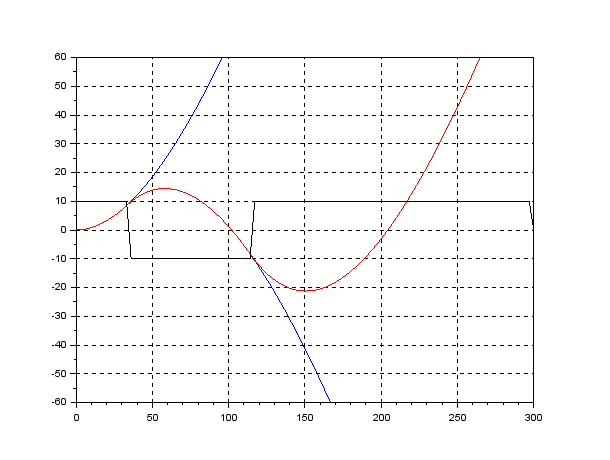
From this response, we used to obtain both time constant and gain constant . However, the response is not always the step response by which a linear system is completely characterized. As a ship has dynamics of an astatic (no-fixed-position) system, the Zig-Zag test is a compromise way for its identification.
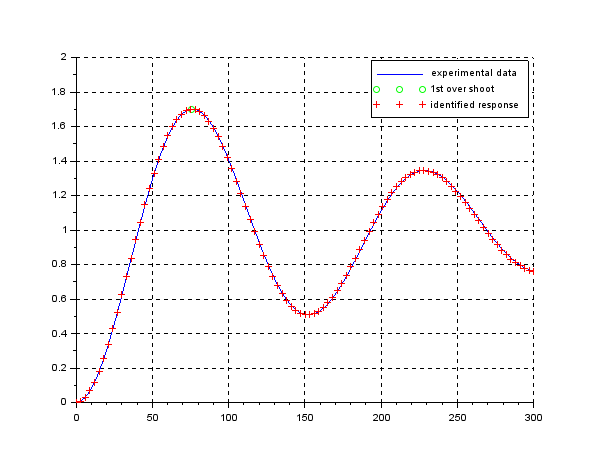
We should notice that if we apply the unity feedback as shown in the above we can obtain the step response and identify  from
from  by the following formula.
by the following formula.

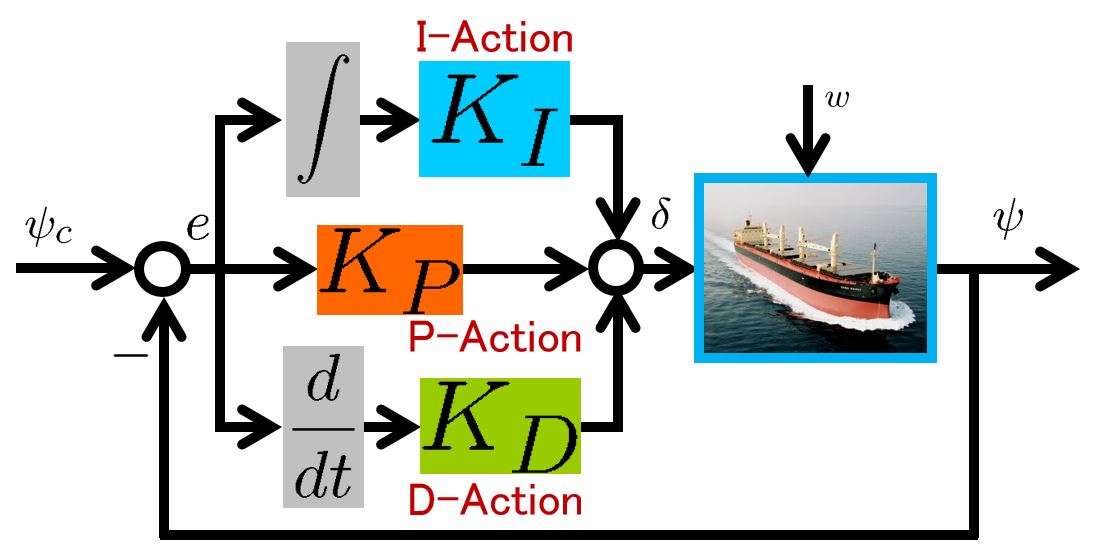
●PID control: Under the nominal forward speed , neglecting the time lag , consider the following NOMOTO model.

Then PID control is presented as follows.

Although we used to tune the P gain  , the D gain
, the D gain  , the I gain
, the I gain  on the site, here we want try to determine them based on the NOMOTO model. The closed-loop system by PID control is given by
on the site, here we want try to determine them based on the NOMOTO model. The closed-loop system by PID control is given by
Here assuming  , we have
, we have

Therefore, we have another configuration of PID control system.
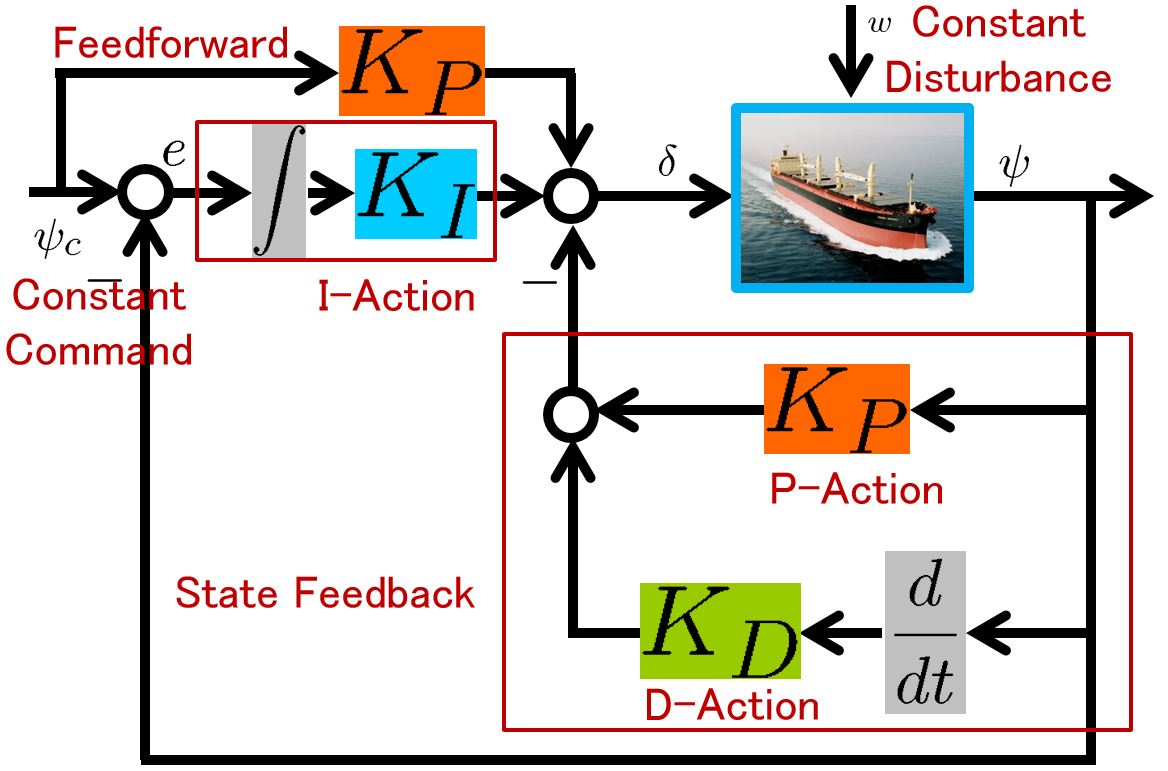
Letting  , the following state equation is obtained.
, the following state equation is obtained.
![\displaystyle{ \underbrace{ \left[\begin{array}{c} \dot{\psi}(t) \\ \dot{r}(t) \end{array}\right] }_{\dot{x}(t)} = \underbrace{ \left[\begin{array}{cc} 0 & 1 \\ 0 & -2\zeta\omega_n \end{array}\right] }_{A} \underbrace{ \left[\begin{array}{c} \psi(t) \\ r(t) \end{array}\right] }_{x(t)} + \underbrace{ \left[\begin{array}{c} 0 \\ \omega_n^2 \end{array}\right] }_{B} \underbrace{\delta(t)}_{u(t)} + \left[\begin{array}{c} 0 \\ w \end{array}\right] }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-4a1aee5f6b09b2cdfe1ab7652b436682_l3.png "Rendered by QuickLaTeX.com")
Then PID control is a state feed back with an integral action as follows.
![\displaystyle{ \underbrace{\delta(t)}_{u(t)} =- \underbrace{ \left[\begin{array}{cc} K_P & K_D \end{array}\right] }_{F} \underbrace{ \left[\begin{array}{c} \psi(t) \\ r(t) \end{array}\right] }_{x(t)} +\underbrace{K_P}_{G} \underbrace{\psi_c}_{v} +K_I \underbrace{\int_0^t(\psi_c-\psi(\tau))\,d\tau}_{x_I(t)} }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-930108f8395d8a1e4622e3ba6c5474d0_l3.png "Rendered by QuickLaTeX.com")
Therefore, after specifying the desired first overshoot  , we calculate the corresponding to
, we calculate the corresponding to  and then determine PID gains by
and then determine PID gains by

Here we try  at first, and then tune it by observing the disturbance rejection.
at first, and then tune it by observing the disturbance rejection.
The CLPS by PID control is presented by
![\displaystyle{ \underbrace{ \left[\begin{array}{c} \dot{\psi}(t) \\ \dot{r}(t) \\ \dot{x}_I(t) \end{array}\right] }_{\dot{x}_{CL}(t)} = \underbrace{ \left[\begin{array}{ccc} 0 & 1 & 0\\ -\omega_n'^2 & -2\zeta'\omega_n' & \omega_I\omega_n'^2 \\ -1 & 0 & 0 \end{array}\right] }_{A_{CL}} \underbrace{ \left[\begin{array}{c} \psi(t) \\ r(t) \\ x_I(t) \end{array}\right] }_{x_{CL}(t)} + \underbrace{ \left[\begin{array}{cc} 0 & 0\\ \omega_n'^2 & 1\\ 1 & 0 \end{array}\right] }_{B_{CL}} \left[\begin{array}{c} \psi_c \\ w \end{array}\right] }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-6220f1085c08a4300d1c579caa0ed438_l3.png "Rendered by QuickLaTeX.com")
Here, assuming  , we differentiate it and obtain
, we differentiate it and obtain
![\displaystyle{ \underbrace{ \left[\begin{array}{c} \ddot{\psi}(t) \\ \ddot{r}(t) \\ \ddot{x}_I(t) \end{array}\right] }_{\ddot{x}_{CL}(t)} = \underbrace{ \left[\begin{array}{ccc} 0 & 1 & 0\\ -\omega_n'^2 & -2\zeta'\omega_n' & \omega_I\omega_n'^2 \\ -1 & 0 & 0 \end{array}\right] }_{A_{CL}} \underbrace{ \left[\begin{array}{c} \dot{\psi}(t) \\ \dot{r}(t) \\ \dot{x}_I(t) \end{array}\right] }_{\dot{x}_{CL}(t)} }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-968db1b1514ee0d76247eda68498a63d_l3.png "Rendered by QuickLaTeX.com")
From the CLPS stability, we have
![\displaystyle{ \underbrace{ \left[\begin{array}{c} \psi(t) \\ r(t) \\ x_I(t) \end{array}\right] }_{x_{CL}} \rightarrow \underbrace{ \left[\begin{array}{ccc} 0 & -1 & 0\\ \omega_n'^2 & 2\zeta'\omega_n' & -\omega_I\omega_n'^2 \\ 1 & 0 & 0 \end{array}\right]^{-1} }_{-A_{CL}^{-1}} \underbrace{ \left[\begin{array}{cc} 0 \\ \omega_n'^2\psi_c +w\\ \psi_c \end{array}\right] }_{B_{CL}} = \left[\begin{array}{cc} \psi_c\\ 0\\ \frac{w}{\omega_I\omega_n'^2} \end{array}\right] }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-cb5b3a5683705b70ec4dd15795c1b402_l3.png "Rendered by QuickLaTeX.com")
This means that the integral action is estimating the unknown disturbance.
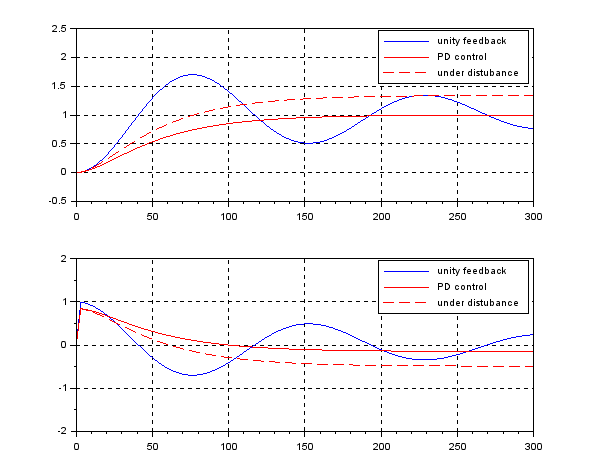
The following simulation shows the CLPS responses by PD control. It is observed that the disturbance rejection is not sufficient because of the lack of integral action.
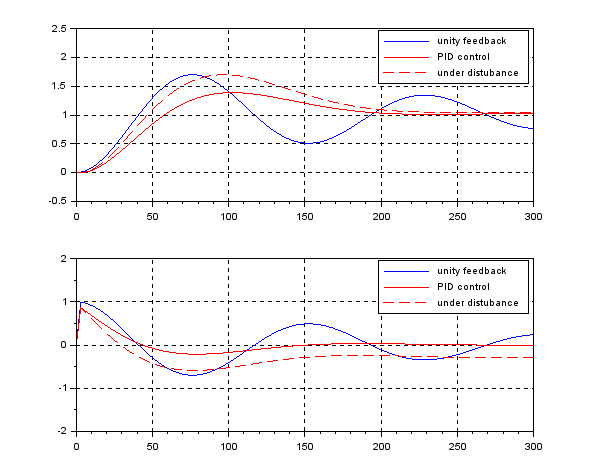
The following simulation shows the CLPS responses by PID control. Here  . It is observed that the disturbance rejection is satisfied but the transient response is fractured a little bit being off expectation.
. It is observed that the disturbance rejection is satisfied but the transient response is fractured a little bit being off expectation.
●LQI control: We will try to determine the PID gains in the framework of LQI control. Consider the following error system:
![\displaystyle{ \left[\begin{array}{c} \dot\psi(t)-\dot{\psi}_c \\ \dot r(t) \\ \dot{\delta}(t) \end{array}\right] = \left[\begin{array}{ccc} 0 & 1 & 0 \\ 0 & -2\zeta\omega_n &\omega_n^2 \\ 0 & 0 & 0 \end{array}\right] \left[\begin{array}{c} \psi(t)-\psi_c \\ r(t) \\ \delta(t) \end{array}\right] + \left[\begin{array}{c} 0 \\ 0 \\ 1 \end{array}\right] \dot{\delta} (t) }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-070f96da6e302ea77182e63b89b5daad_l3.png "Rendered by QuickLaTeX.com")
For the error system, we will minimize the following criterion function:

Solving this problem, the PID gains are obtained as follows:
![\displaystyle{ \dot{\delta}(t) =- \left[\begin{array}{ccc} f_\psi & f_r & f_\delta \end{array}\right] \left[\begin{array}{c} \psi(t)-\psi_c \\ r(t) \\ \delta(t) \end{array}\right] }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-78bdbd6a02cdc112e35492f7b66c2813_l3.png "Rendered by QuickLaTeX.com")
![\displaystyle{ =- \underbrace{ \left[\begin{array}{ccc} f_\psi & f_r & f_\delta \end{array}\right] \left[\begin{array}{ccc} 0 & 1 & 0 \\ 0 & -2\zeta\omega_n &\omega_n^2 \\ 1 & 0 & 0 \end{array}\right]^{-1} }_{ \left[\begin{array}{ccc} K_P & K_D & K_I \end{array}\right] } \left[\begin{array}{c} \dot\psi(t)-\dot{\psi}_c \\ \dot{r}(t) \\ \psi(t)-\psi_c \end{array}\right] }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-bfcd4ed97bb6d3d92a95153aacf8d555_l3.png "Rendered by QuickLaTeX.com")
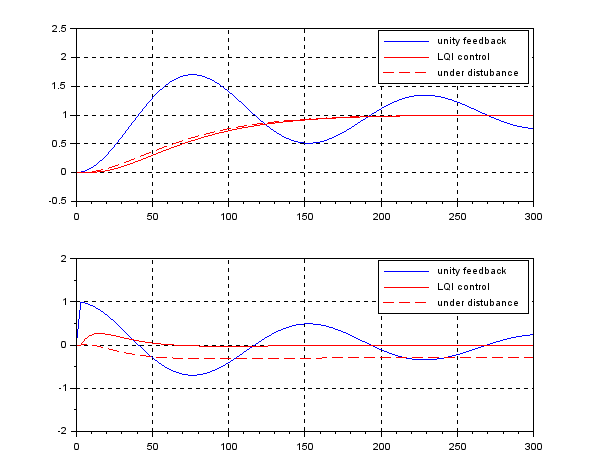
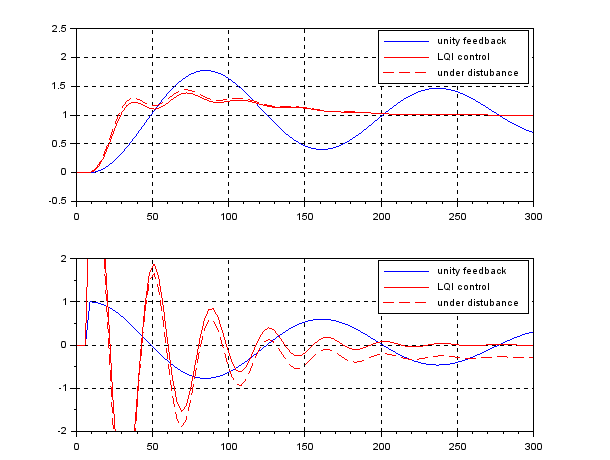
In the case of  , we have the following simulation result, which seems to be very nice. Note that there is no feedforward term compared with PID control.
, we have the following simulation result, which seems to be very nice. Note that there is no feedforward term compared with PID control.
However, in the case of having the time lag  , the CLPS is unstable as follows:
, the CLPS is unstable as follows:
●LPV control:
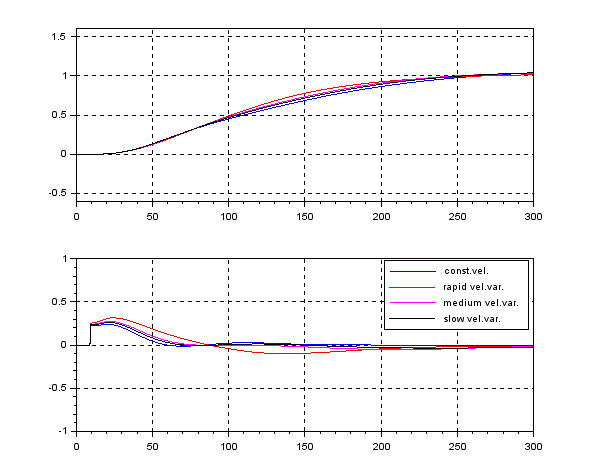
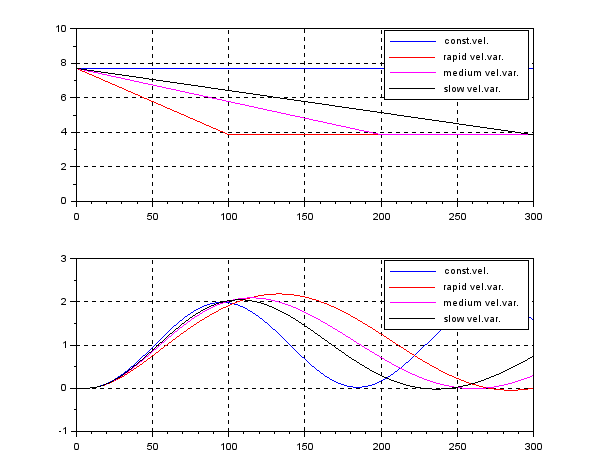
Assuming the following speed variation, the responses of CLPS by unity feedback vary largely.
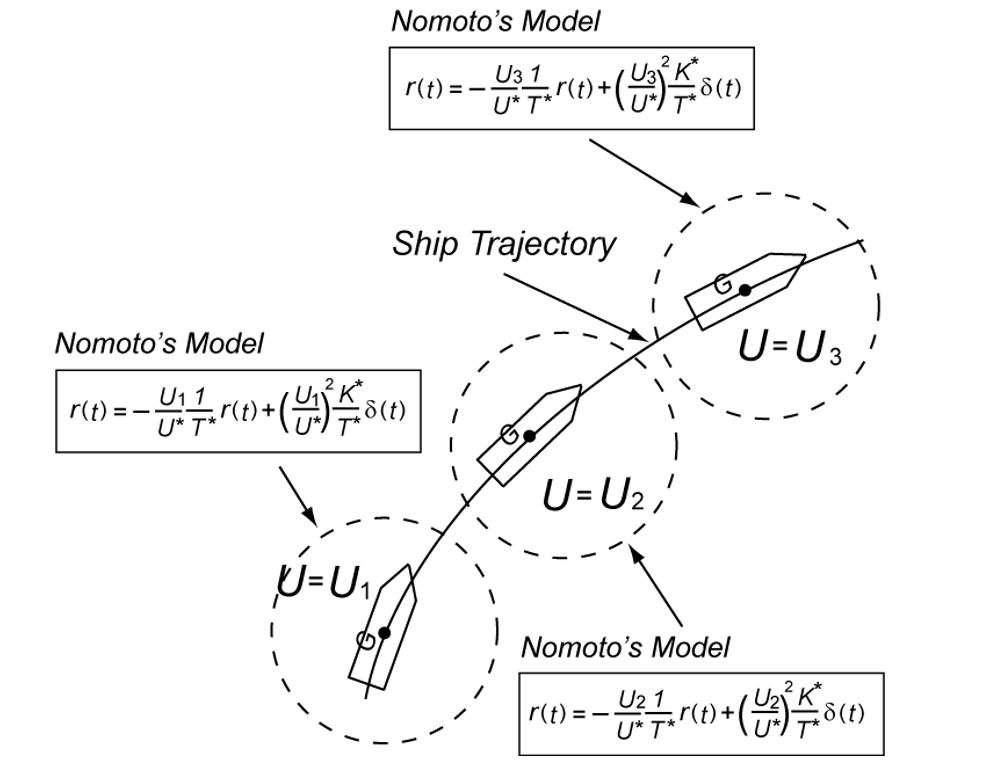
Consider the following NOMOTO model based on a nominal forward speed .

Adding the rudder dynamics,

we have the following state-space representation.
![\displaystyle{ \underbrace{ \left[\begin{array}{c} \dot{\psi}(t) \\ \dot{r}(t) \\ \dot{\delta}(t) \end{array}\right] }_{\dot{x}(t)} = \underbrace{ \left[\begin{array}{ccc} 0 & 1 & 0\\ 0 & -\left(\frac{U}{U^*}\right)\frac{1}{T^*} & \left(\frac{U}{U^*}\right)^2\frac{K^*}{T^*} \\ 0 & 0 & -\frac{1}{T_a} \end{array}\right] }_{A(U,U^2)} \underbrace{ \left[\begin{array}{c} \psi(t) \\ r(t) \\ \delta(t) \end{array}\right] }_{x(t)} + \underbrace{ \left[\begin{array}{c} 0 \\ 0 \\ \frac{K_a}{T_a} \end{array}\right] }_{B} u(t) }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-3d725574d98be967189e786862a42f9a_l3.png "Rendered by QuickLaTeX.com")
![\displaystyle{ \underbrace{ \psi(t) }_{y(t)} = \underbrace{ \left[\begin{array}{ccc} 1 & 0 & 0 \end{array}\right] }_{C} \underbrace{ \left[\begin{array}{c} \psi(t) \\ r(t) \\ \delta(t) \end{array}\right] }_{x(t)} }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-067f0588c517bfa5ab508b0cb5faafb1_l3.png "Rendered by QuickLaTeX.com")
Note that it is possible to have the following polytopic representation.
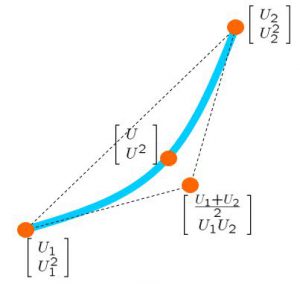

where



Defining  ,
,
![\displaystyle{ p_1(U,U^2)=\frac{1}{p_0}\det \left[\begin{array}{cc} U-U_3 & U_2-U_3 \\ U^2-U_1U_2 & U_2^2-U_1U_2 \\ \end{array}\right]}](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-627147d93931c456a5b18b3435f469d2_l3.png "Rendered by QuickLaTeX.com")
![\displaystyle{ p_2(U,U^2)=\frac{1}{p_0}\det \left[\begin{array}{cc} U_1-U_3 & U-U_3 \\ U_1^2-U_1U_2 & U^2-U_1U_2 \\ \end{array}\right]}](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-1f8bd8469d4718f4520c38222d56b81d_l3.png "Rendered by QuickLaTeX.com")
![\displaystyle{ p_3(U,U^2)=\frac{1}{p_0}\det \left[\begin{array}{cc} U_1-U_2 & U_2-U \\ U_1^2-U_2^2 & U_2^2-U^2 \\ \end{array}\right]}](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-76793f65b53181b82702570329e95043_l3.png "Rendered by QuickLaTeX.com")
![\displaystyle{ p_0=\det \left[\begin{array}{cc} U_1-U_2 & U_2-U_3 \\ U_1^2-U_2^2 & U_2^2-U_1U_2 \\ \end{array}\right]}](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-53cc0ba5757c30920dfac62c82d7398c_l3.png "Rendered by QuickLaTeX.com")

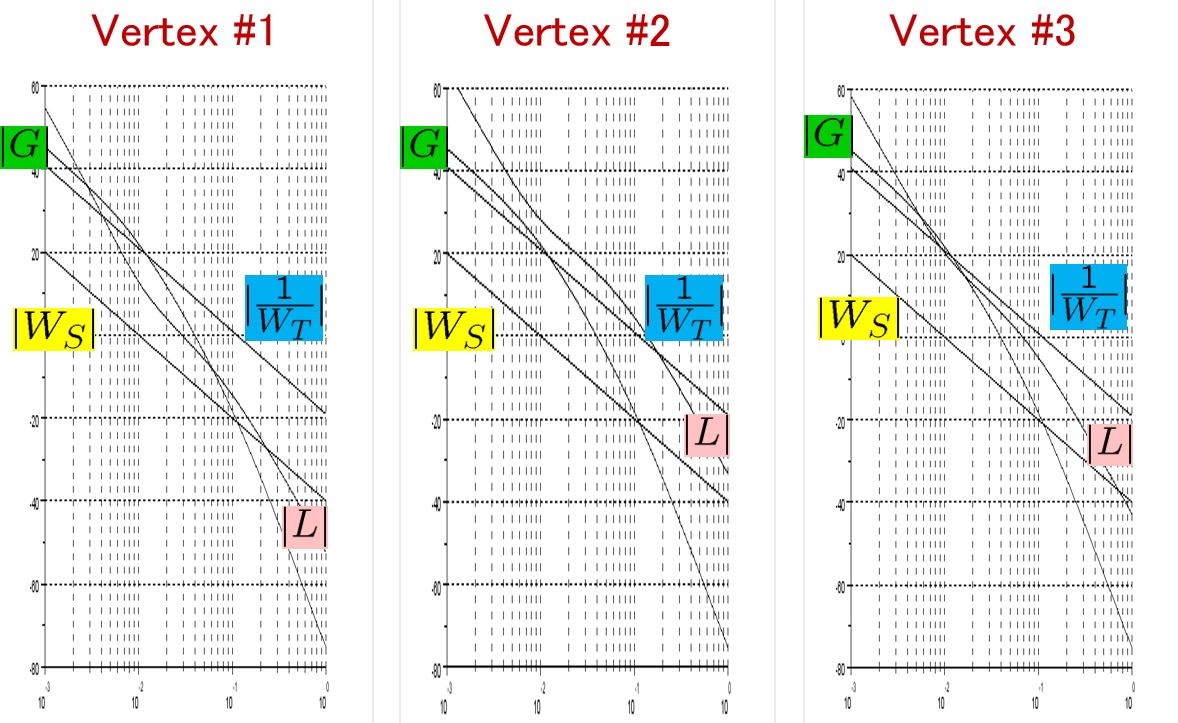
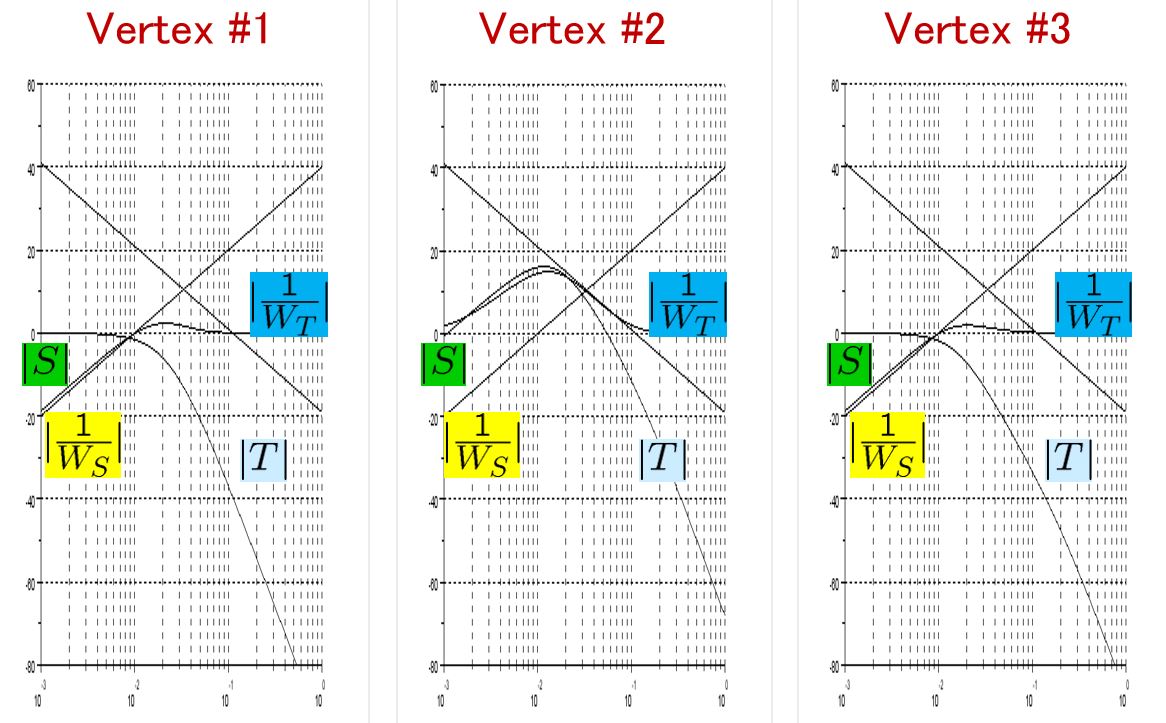
Based on this model, the framework of LPV control is proposed. LPV control can cover the variation included in the triangle region with the vertexes  ,
,  and temporal vertex
and temporal vertex  .
.
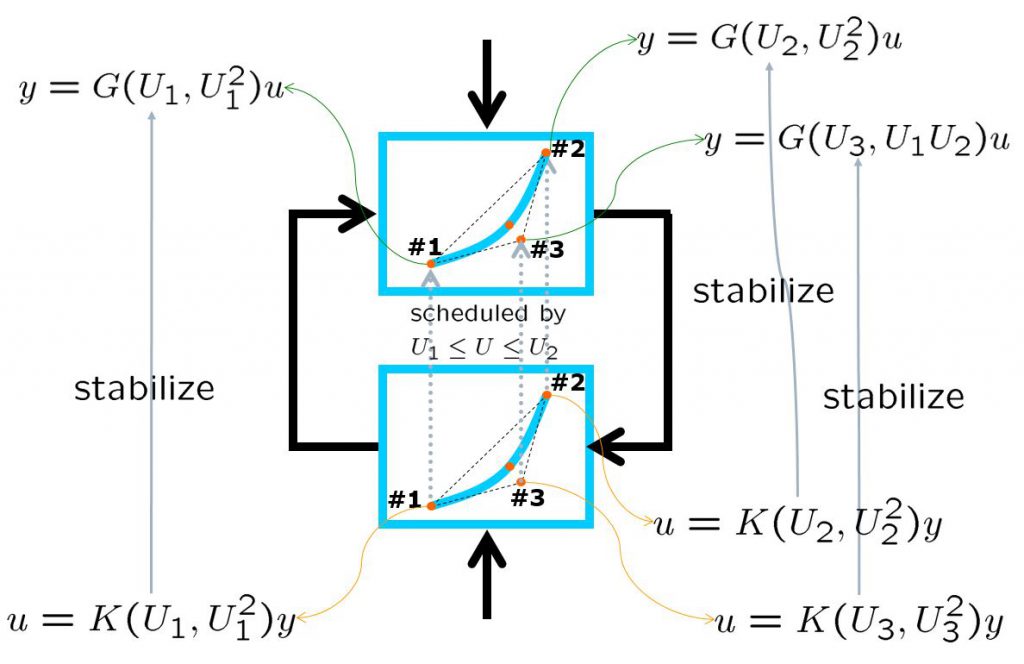
Constitute the following 2-port system.
![\displaystyle{ P: \left\{\begin{array}{l} \left[\begin{array}{c} \dot{x} \\ \dot{x}_I \end{array}\right]= \underbrace{ \left[\begin{array}{cc} A(U,U^2)& 0 \\ -C & 0 \end{array}\right] }_{\cal{A}(U,U^2)} \left[\begin{array}{c} x \\ x_I \end{array}\right] + \underbrace{ \left[\begin{array}{c} 0 \\ 1 \end{array}\right] }_{B_1} r + \underbrace{\left[\begin{array}{c} B \\ 0 \end{array}\right] }_{B_2} u\\ \underbrace{ \left[\begin{array}{c} y_{11} \\ y_{12} \end{array}\right] }_{y_1} = \underbrace{ \left[\begin{array}{cc} 0 &\omega_I\\ \omega_DCA(U,U^2) & 0 \end{array}\right] }_{C_1} \left[\begin{array}{c} x \\ x_I \end{array}\right] + \underbrace{ \left[\begin{array}{c} 0 \\ 0 \end{array}\right] }_{D_{11}} r + \underbrace{ \left[\begin{array}{c} 0 \\ \omega_DCB \end{array}\right] }_{D_{12}} u\\ \underbrace{ \left[\begin{array}{c} y \\ x_I \end{array}\right] }_{y_2} = \underbrace{ \left[\begin{array}{cc} C & 0\\ 0 & 1 \end{array}\right] }_{C_2} \left[\begin{array}{c} x \\ x_I \end{array}\right] + \underbrace{ \left[\begin{array}{c} 0 \\ 0 \end{array}\right] }_{D_{21}} r \end{array}\right.}](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-53e2d7d1439b485ab0a651fb593485bc_l3.png "Rendered by QuickLaTeX.com")

For this LPV model, design the following LPV controller.
![\displaystyle{ K_0: \left\{\begin{array}{l} \dot{x}_K=A_K(U,U^2)x_K+ \underbrace{ \left[\begin{array}{cc} B_K^{(1)}(U,U^2) & B_K^{(2)}(U,U^2) \end{array}\right] }_{B_K(U,U^2)} \left[\begin{array}{c} y \\ x_I \end{array}\right] \\ u=C_K(U,U^2)x_K + \underbrace{ \left[\begin{array}{cc} D_K^{(1)}(U,U^2) & D_K^{(2)}(U,U^2) \end{array}\right] }_{D_K(U,U^2)} \left[\begin{array}{c} y \\ x_I \end{array}\right] \end{array}\right.}](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-54e444239e49a80798f6b2b19731a663_l3.png "Rendered by QuickLaTeX.com")




Form this, the following output feedback is obtained.
![\displaystyle{ K: \left\{\begin{array}{l} \left[\begin{array}{c} \dot{x}_K \\ \dot{x}_I \end{array}\right]= \underbrace{ \left[\begin{array}{cc} A_K(U,U^2) & B_K^{(2)}(U,U^2) \\ 0 & 0 \end{array}\right] }_{A_K(U,U^2)} \left[\begin{array}{c} x_K \\ x_I \end{array}\right] + \underbrace{ \left[\begin{array}{cc} B_K^{(1)}(U,U^2) & 0\\ -1& 1 \end{array}\right] }_{B_K(U,U^2)} \left[\begin{array}{c} y \\ r \end{array}\right] \\ u= \underbrace{ \left[\begin{array}{cc} C_K(U,U^2) & D_K^{(2)}(U,U^2) \end{array}\right] }_{C_K(U,U^2)} \left[\begin{array}{c} x_K \\ x_I \end{array}\right] + \underbrace{ \left[\begin{array}{cc} D_K^{(1)}(U,U^2) & 0 \end{array}\right] }_{D_K(U,U^2)} \left[\begin{array}{c} y \\ r \end{array}\right] \end{array}\right. }](https://cacsd1.sakura.ne.jp/wp/wp-content/ql-cache/quicklatex.com-c54a60ae350f5490f5fc7c4c58f49a2b_l3.png "Rendered by QuickLaTeX.com")
We can obtain  control by fixing as
control by fixing as  . The following simulation shows the CLPS responses by control. It is observed that the responses are slightly varied according to the three kinds of speed variation.
. The following simulation shows the CLPS responses by control. It is observed that the responses are slightly varied according to the three kinds of speed variation.
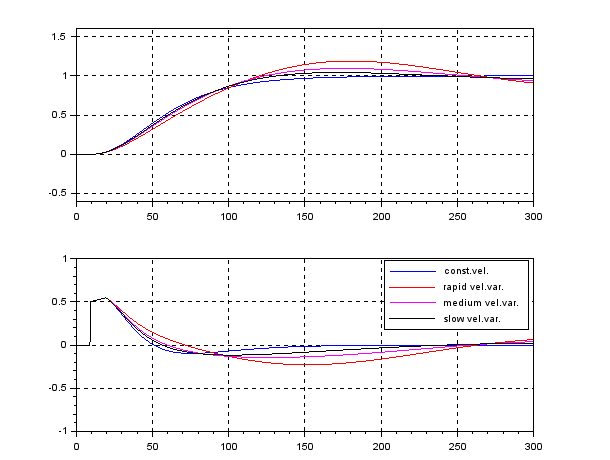
On the other hand, the following simulation shows the CLPS responses by the LPV control. It is observed that the responses are almost same in spite of the three kinds of speed variation.